Tras el fallecimiento de Kobe Bryant me comprometí a postear una serie de entradas relacionadas a él. En esta oportunidad haremos un análisis exploratorio de Kobe Bryant desde la óptica de los tiros que tomó en sus 20 años de carrera profesional.
La data que utilizaremos para este análisis tiene la ubicación de cada tiro tomado por Kobe, resultando muy interesante y tentadora para hacer valoraciones y críticas, pero la verdad es que tiene limitaciones para comprender lo legendario de cada tiro tomado por Kobe Bryant.
Las limitaciones que tiene los registros de tiro para hacer valoraciones profundas sobre la selección de tiro de un jugador son muchas, así que voy a resaltar algunas para justificar las razones por las que no haré valoraciones, además de mi condición de fanático e inexperto.
Limitaciones:
- No hay detalles de la defensa. No sabemos a qué distancia estaba el defensor más cercano, cuantos defensores había, quienes estaba defendiendo (Hay defensores más hábiles que otros)
- No hay detalles que los malabares que hizo para llegar a determinada posición.
- Esta data puede conducir a interpretaciones burdas, alguien podría concluir que como debajo del aro la eficiencia de tiro de un jugador es mayor, pues debería tomar más tiros de esa zona, cuando en realidad llegar a esa zona es bastante complicado y quizás incremente mucho la posibilidad de pérdidas de balón.
- No hay detalles de la posición de los compañeros en la cancha, ni de quienes eran. No podemos decir si había una opción de tiro mejor (Difícil que haya una opción mejor a que Kobe la tire).
Por estas razones me limitaré a ser completamente descriptivo en este post, además de equilibrar adecuadamente la interpretación de las visualizaciones y los comentarios sobre los detalles y estrategias utilizadas para generarlas. Esto para no aburrir a los que entren a leer sin interés muy profundo en el código, o viceversa.
Para reproducir el contenido
Como de costumbre, compartiré el enlace al repositorio de la publicación en github, pero esta vez y quizás en las próximas ocasiones, compartiré también el enlace del proyecto en rstudio.cloud. Esta segunda opción garantiza la reproducción de todo el contenido, al poner una sección de R en el navegador, con todos los paquetes y archivos utilizados para crear el material.
Por otro lado, con el fin de lograr visualizaciones llamativas intenté varias opciones para incorporar los segmentos de la cancha en los gráficos. El primer intento fue colocar una imagen de fondo en los gráficos, pero no lograba ajustar bien las dimensiones y quedaba feo. El segundo intento consistió dibujar las líneas con ggplot2. Para lograr esto me auxilié del código de varias personas, principalmente el de Todd Wschneider que a su vez se basó en las publicaciones de Savvas Tjortjoglou (por eso amo mundo open source). Menciono esto porque las adaptaciones que le hice a lo que ellos hicieron fueron extensas y por sí solas representarían una publicación individual, pero igual pueden acceder a todos los objetos desde el workspace en los repositorios.
La data
La data para este análisis es una publicada en kaggle para una competencia de machine learning. El objetivo de la competencia es utilizar un set de los tiros tomados por Kobe y construir un modelo que clasifique si una serie de observaciones, para las cuales no tenemos el resultado, fueron encestados o no.
Entre las variables que constituyen el set de datos se encuentran las siguientes:
- Ubicación del tiro, con coordenadas en escala a las dimensiones de una chancha de basket.
- Zona del tiro
- Distancia respecto al aro
- Tiempo restante del cuarto
- Tipo de tiro (tablerito, gancho, donqueo, jump shot)
- Id del juego
- Equipo contrincante
- Si el tiro se tomó en playoff o serie regular
- Fecha del juego
- Resultado del lanzamiento (acierto o fallo)
Aquí el enlace de la competencia con los detalles sobre el set de datos, el enlace original de descarga y algunos notebooks de gente que ha compartido sus análisis y modelos. Es probable que en unos días yo publique el mío también.
Manos a la obra
# Paquetes
library(tidyverse)
library(ggthemes)
library(patchwork)
library(tidytext) # para usar reorder_within() y scale_y_reordered()
# Función para crear los segmentos de la chancha
# Esta función fue creada en base al trabajo de Todd Wschneider
source("scripts/court_plot.R")
# Importando la data
shots_data <- read_csv("data.csv") %>%
# Unas simples transformaciones a las coordenadas de los tiros
# para que sean congruente con la escla de court_points
mutate(
loc_x = loc_x/10,
loc_y = (loc_y + 50)/10
)
# Puntos de la cancha
court_points <- generate_court_points()La verdad es que kobe tiraba mucho, tomaba tiros muy difíciles con mucha frecuencia y eso lo llevó a marcar un porcentaje de aciertos cuestionable para algunos. En toda su carrea lanzó cerca de 45% de campo, pero aun así se colocó en el top tres de anotadores de la historia de la NBA (Lebron le pasó días antes de su muerte), también deleitó al mundo con una serie de canastos inigualables.
En general y sin considerar los tiros libres, kobe tomó 30,697 tiros de campo, de los cuales 24,271 fueron intentos de dos puntos (79.1%) y 6,426 fueron intentos detrás de la línea de tres.
shots_data %>%
count(shot_type) %>%
janitor::adorn_totals("row")## shot_type n
## 2PT Field Goal 24271
## 3PT Field Goal 6426
## Total 30697El primer gráfico muestra la distribución de estos tiros en las diferentes temporadas. Kobe tomó más de 1,000 tiros en la mayoría de las temporadas que jugó y solo tomó menos de 750 tiros en los años de novato y en los años tras la lesión del tendón de Aquiles.
# Gráfico de la cantidad de tiros
p1 <- shots_data %>%
group_by(season = parse_number(season), shot_type) %>%
summarise(fg_percent = mean(shot_made_flag, na.rm = TRUE),
tiros = n()) %>%
ggplot(aes(x = season, y = tiros, color = shot_type)) +
geom_line() +
geom_point() +
scale_y_continuous(labels = scales::comma) +
theme_light() +
scale_color_tableau() +
theme(
legend.position = "none",
axis.text.x = element_blank(),
axis.title.x = element_blank()
) +
labs(
x = "",
y = "Tiros",
title = "Cantidad de tiros y porcentaje de aciertos por temporada"
)
# Gráfico del porcentaje de campo
p2 <- shots_data %>%
group_by(season = parse_number(season), shot_type) %>%
summarise(
fg_percent = mean(shot_made_flag, na.rm = TRUE),
tiros = n()
) %>%
ggplot(aes(x = season, y = fg_percent, color = shot_type)) +
geom_line() +
geom_point() +
scale_y_continuous(labels = scales::percent) +
coord_cartesian(ylim = c(0, 0.60)) +
theme_light() +
scale_color_tableau() +
theme(
legend.position = "bottom"
) +
labs(x = "Temporada", y = "Porcentaje")
p1 / p2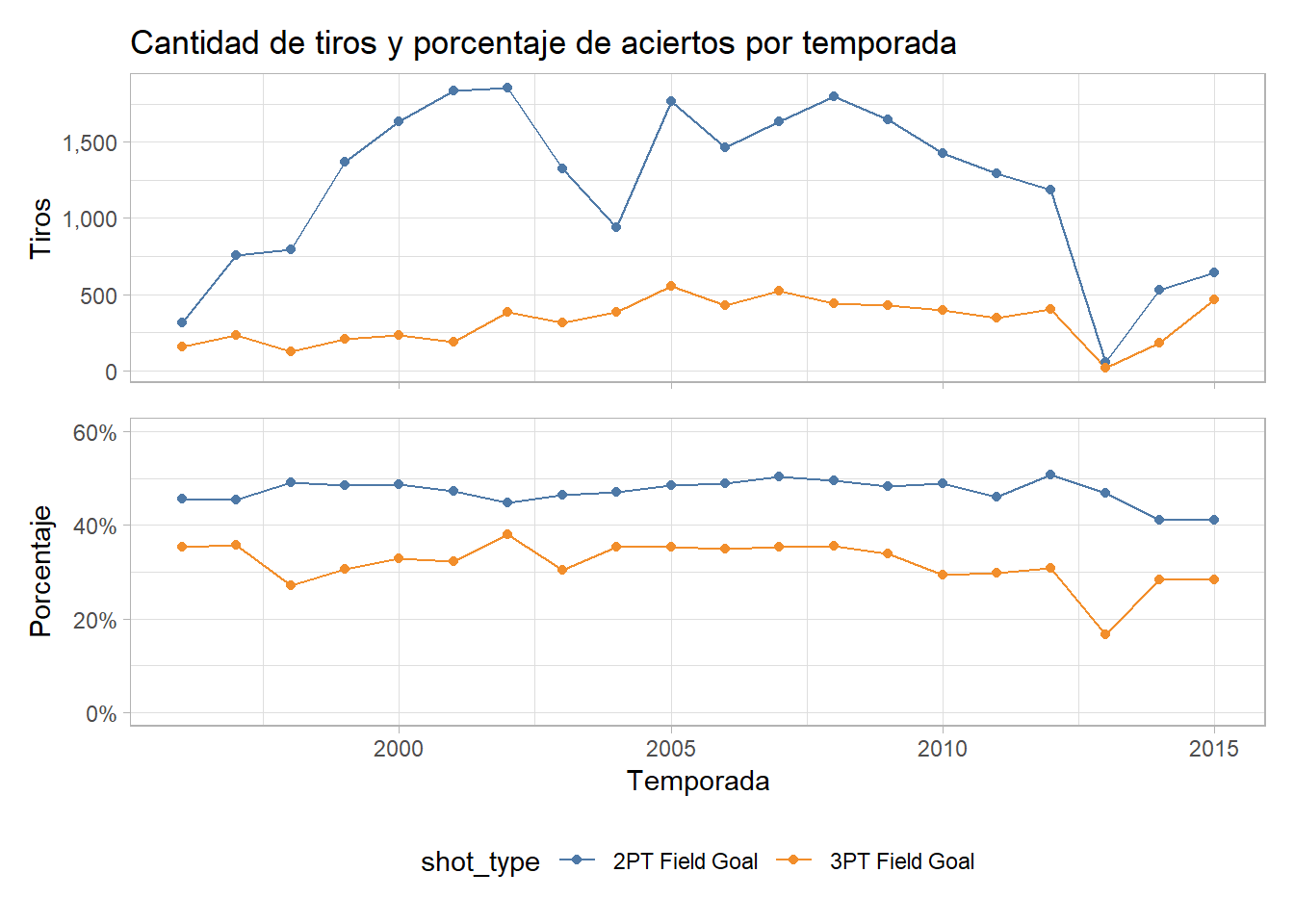
Las siguientes visualizaciones exploran los tiros tomados por Kobe, pero enfocándose en la posición de la cancha en la que los tomó. Indudablemente el lugar del tiro influye mucho en la probabilidad de acierto, muchas veces los tiros más alejados suelen fallarse más, o los del lado opuesto a la mano dominante, etc. El set de datos trae 2 variables categóricas con la posición de la cancha en la que se tomó el tiro, por tanto, podemos ver la cantidad y el porcentaje de acierto en cada zona.
Estos gráficos introducen dos cuestiones novedosas:
Usan la función
reorder_within()del paquete{tidytext}, creado por Julia Silge y David Robinson, que permite tener gráficos en facets con ejes organizados independientemente.Usar todo un gráfico como anotación en otro gráfico. Esto puede tener una gran variedad de usos, pero en este caso se utiliza para colocar una leyenda interesante al gráfico. De esta forma hasta alguien poco familiarizado con las dimensiones de una chancha entendería a qué área se refiere cada barra.
# Gráfico que funguirá como leyenda
shot_zone2 <- shots_data %>%
# excluyendo los tiros antes de cruzar la media chancha
filter(shot_zone_area != "Back Court(BC)") %>%
ggplot() +
geom_point(aes(
x = loc_x, y = loc_y,
color = shot_zone_area), show.legend = FALSE) +
# Agregando las líneas de la chancha
geom_path(
data = court_points,
aes(x = x, y = y, group = desc)
) +
# Tema sin elementos visuales
theme_void() +
# Mover la leyenda
theme(legend.position = "right") +
# una escala de color bonita
scale_color_tableau()
# Gráfico de barras con los tiros y porcentaje de tiro por zona
shots_data %>%
filter(shot_zone_area != "Back Court(BC)") %>%
group_by(shot_zone_area) %>%
summarise(
tiros = n(),
porcentaje = mean(shot_made_flag, na.rm = TRUE)
) %>%
# colocando la data en formato largo
# en el futuro usen pivote_longer
gather(medida, valor, -shot_zone_area) %>%
mutate(
medida = factor(medida, labels = c("Porcentaje de tiro", "Cantidad de tiros"))
) %>%
ggplot(aes(
# Creando el factor organizado individualmenet
x = tidytext::reorder_within(shot_zone_area, by = desc(valor), within = medida),
y = valor,
fill = shot_zone_area)
) +
geom_col(show.legend = FALSE, alpha = 0.8) +
facet_wrap(~medida, scales = "free") +
tidytext::scale_x_reordered() +
coord_flip() +
# Agregando el gráfico anterior como anotación
annotation_custom(ggplotGrob(shot_zone2), xmin = 3.8, xmax = 5.5, ymin = 6500, ymax = 12000) +
theme_minimal() +
scale_y_continuous(labels = function(x) format(x, big.mark = ",", digits = 2)) +
theme(
strip.text = element_text(size = 12, face = "bold")
) +
labs(x = "",
y = "",
title = "Tiros tomados y eficiencia en diferentes zonas de la cancha") +
scale_fill_tableau()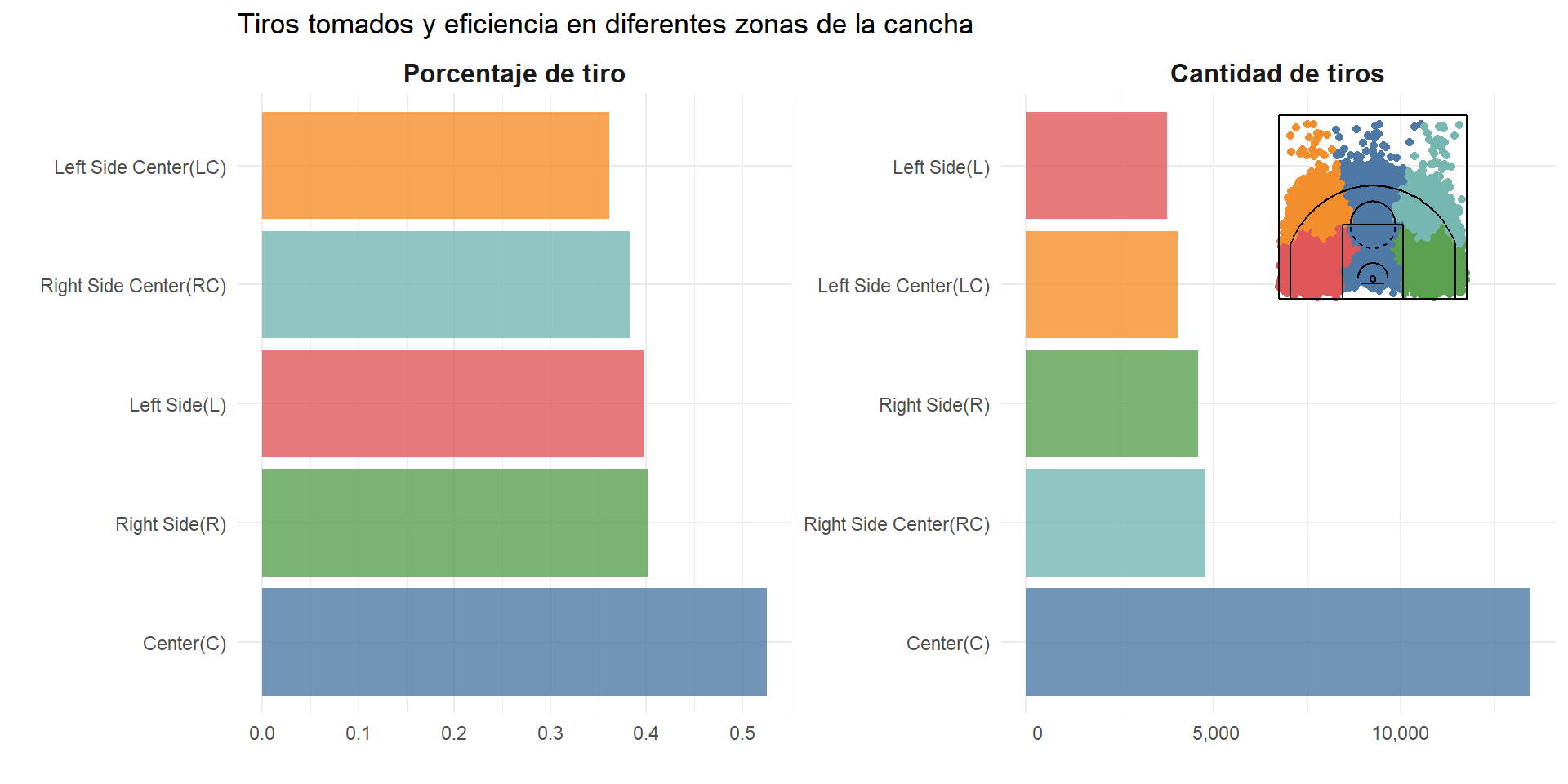
shot_zone <- shots_data %>%
filter(shot_zone_basic != "Backcourt") %>%
ggplot() +
geom_point(
aes(x = loc_x, y = loc_y,
color = shot_zone_basic), show.legend = FALSE
) +
geom_path(
data = court_points,
aes(x = x, y = y, group = desc)
) +
theme(
axis.text =
) +
theme_void() +
theme(legend.position = "right") +
labs() +
scale_color_tableau()
shots_data %>%
filter(shot_zone_basic != "Backcourt") %>%
group_by(shot_zone_basic) %>%
summarise(
tiros = n(),
porcentaje = mean(shot_made_flag, na.rm = TRUE)
) %>%
gather(medida, valor, -shot_zone_basic) %>%
mutate(
medida = factor(medida, labels = c("Porcentaje de tiro", "Cantidad de tiros"))
) %>%
ggplot(aes(
x = tidytext::reorder_within(shot_zone_basic, desc(valor), medida),
y = valor,
fill = shot_zone_basic)) +
geom_col(show.legend = FALSE, alpha = 0.8) +
facet_wrap(~medida, scales = "free") +
tidytext::scale_x_reordered() +
coord_flip() +
annotation_custom(
ggplotGrob(shot_zone),
xmin = 4, xmax = 6,
ymin = 6500, ymax = 12000
) +
theme_minimal() +
scale_y_continuous(labels = function(x) format(x, big.mark = ",", digits = 2)) +
theme(
strip.text = element_text(size = 12, face = "bold")
) +
labs(x = "",
y = "",
title = "Tiros tomados y eficiencia en diferentes zonas de la cancha") +
scale_fill_tableau()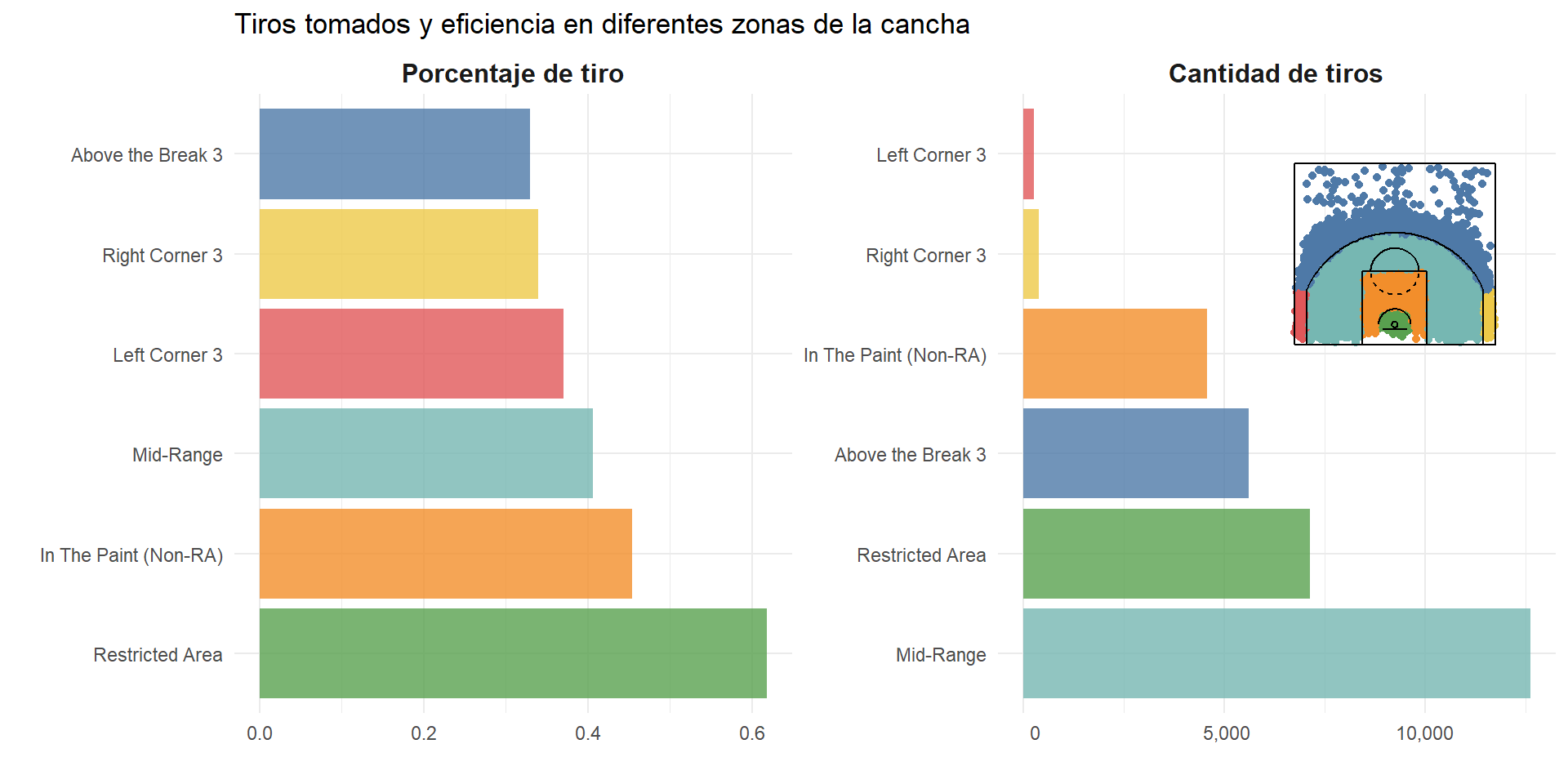
Sin duda la data categórica es interesante, pero resulta más emocionante ver un gráfico de los tiros individuales. Igual, al estar hablando de más de 30,000 puntos, un poco de overlapping no debería sorprender. Hay que buscar estrategias para lidear con esto, porque en general el gráfico de puntos no deja ver mucho sobre las zonas en las que kobe era más efectivo o, simplemente, tiraba más.
shots_data %>%
filter(shot_zone_basic != "Backcourt") %>%
ggplot(aes(x = loc_x, y = loc_y )) +
geom_point(alpha = 0.5, aes(color = factor(shot_made_flag))) +
geom_path(
data = court_points,
aes(x = x, y = y, group = desc)
) +
scale_color_tableau(labels = c("Fallados", "Acertados")) +
theme(
axis.text = element_blank(),
axis.title = element_blank(),
panel.grid = element_blank(),
axis.ticks = element_blank(),
panel.background = element_blank(),
legend.position = "bottom"
) +
labs(color = "") +
coord_cartesian(expand = FALSE) +
ggtitle("Distribución de los tiros de Kobe")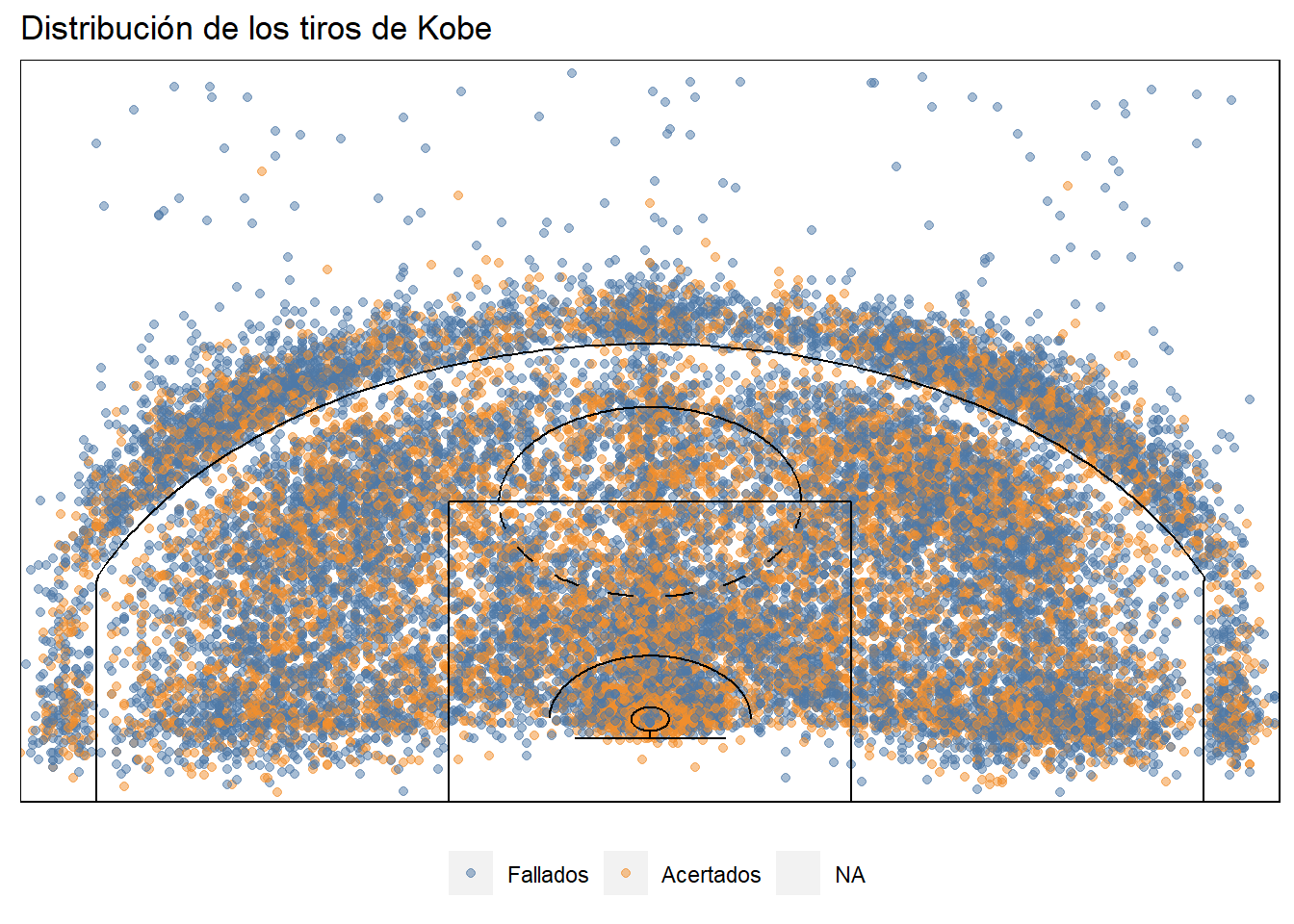
Hay distintas estrategias para lidiar con el overlapping. Entre las más comunes está diminuir la transparencia de los puntos y esperar que las zonas de mayor concentración queden con un color más oscuro. Por otro lado se puede utilizar una geometría especial como hexbin::geom_hex() que crea una especie de histograma bidimensional, en el que divide el espacio en binds hexagonales y cada uno toma color en función a la cantidad de puntos que cae en ellos.
Las geometrías de densidad bidimensional son otra opción para lidiar con este “problema”. Estas facilitan mucho la interpretación porque agrupan las observaciones, en “círculos” con similar cantidad de puntos, de modo los círculos más pequeños tienen mayor densidad. También son una forma de representar en dos dimensiones algo que podría verse en tres.
Aquí se muestran tanto la versión en 2d como la versión 3d. Ahora es más fácil ver de dónde metía y fallaba más Kobe.
Para más ejemplos de cómo lidiar con overlapping pueden consultar las siguientes fuentes: from data to viz y [R graph gallery], ambas creaciones de Yan Holtz.
shots_data %>%
filter(!is.na(shot_made_flag)) %>%
filter(combined_shot_type == "Jump Shot", shot_zone_basic != "Backcourt") %>%
mutate(shot_made_flag = factor(shot_made_flag, labels = c("Fallados", "Anotados"))) %>%
ggplot() +
stat_density2d(
geom = 'polygon',
contour = T,
n = 100,
aes(x = loc_x,
y = loc_y,
color = shot_made_flag,
fill = ..level../max(..level..),
alpha = ..level..)
) +
geom_path(
data = court_points,
aes(x = x, y = y, group = desc)
) +
guides(alpha = FALSE, color = FALSE) +
facet_wrap(~shot_made_flag) +
theme(
axis.text = element_blank(),
axis.title = element_blank(),
panel.grid = element_blank(),
axis.ticks = element_blank(),
panel.background = element_blank(),
strip.text = element_text(size = 12),
legend.position = "bottom"
) +
labs(title = "Densidad de la distribución de los tiros") +
scale_fill_viridis_c(
option = "magma"
)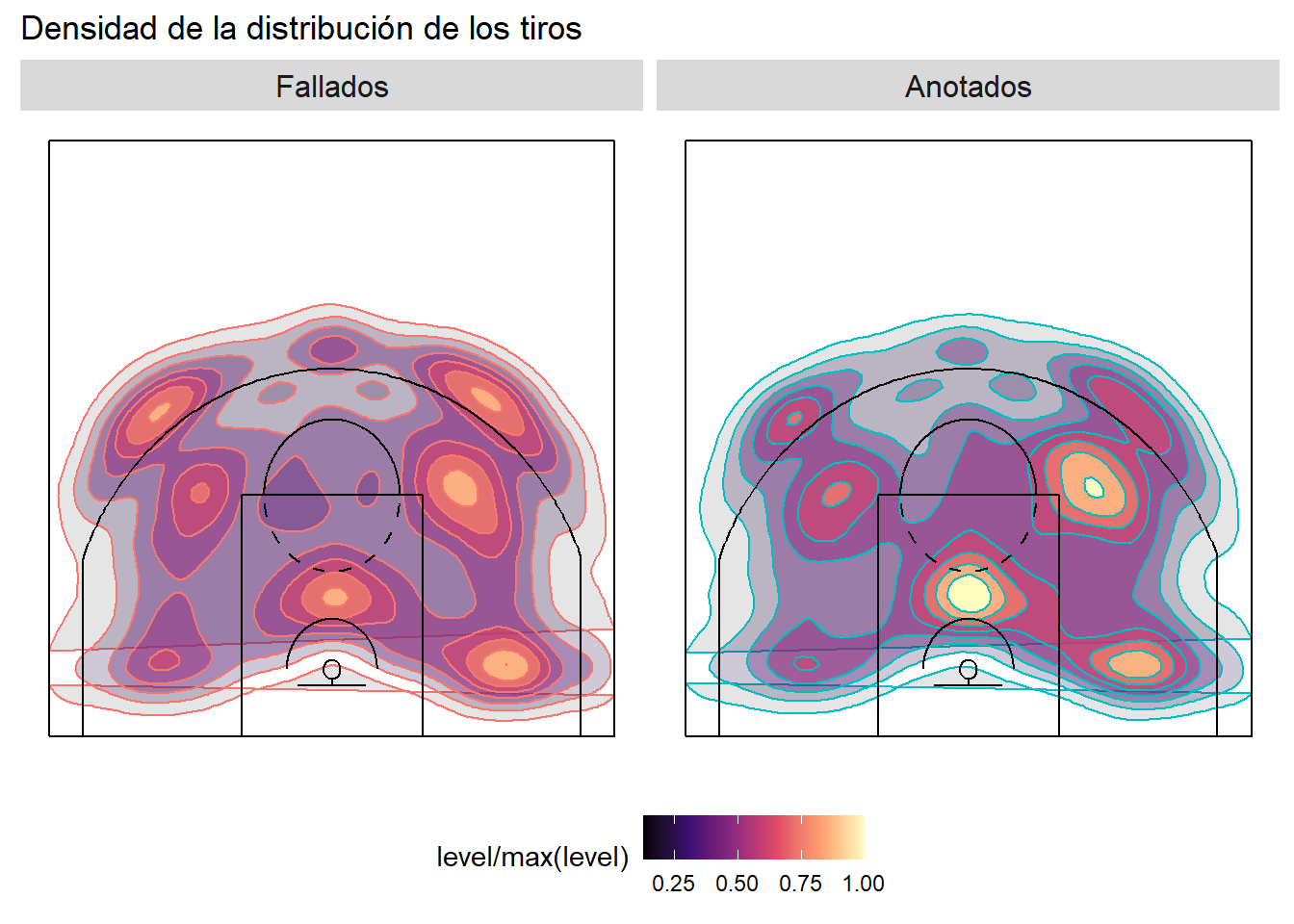
Grafíco 3D de la distribución de tiros.
kd_shots <- with(
subset(shots_data, action_type == "Jump Shot" & shot_made_flag == 1),
MASS::kde2d(loc_x, loc_y, n = 30)
)
plotly::plot_ly(x = kd_shots$x, y = kd_shots$y, z = kd_shots$z) %>% plotly::add_surface()Otra forma de verlo es usando la geometría geom_raster(). Esta se usó una vez en la publicación sobre las defunciones en República Dominicana.
En estos casos solo se grafican los jump shots porque incluir otros, como dunks, que fueron muchos y casi no los fallaba, le quita un poco de gracia a la visualización.
En general, Kobe no transformó considerablemente su selección de tiro a lo largo de su carrera.
#c("1999-00", "2000-01", "2001-02", "2008-09", "2009-10")
shots_data %>%
filter(combined_shot_type == "Jump Shot",
shot_zone_basic != "Backcourt",
season %in% c("2008-09", "2009-10"),
!is.na(shot_made_flag))%>%
ggplot() +
stat_density2d(
aes(x = loc_x,
y = loc_y,
fill = stat(density/ max(density))),
geom = "raster",
contour = FALSE,
interpolate = TRUE,
n = 50) +
geom_path(
data = court_points,
aes(x = x, y = y, group = desc),
color = "white"
) +
facet_wrap(~season) +
scale_fill_viridis_c(
"Frecuencia",
limits = c(0, 1),
breaks = c(0, 0.5, 1),
labels = c("baja", "media", "alta"),
option = "magma",
guide = guide_colorbar(barwidth = 10)
) +
theme(
axis.text = element_blank(),
axis.title = element_blank(),
panel.grid = element_blank(),
axis.ticks = element_blank(),
panel.background = element_blank(),
strip.text = element_text(size = 12),
legend.position = "bottom"
) +
labs(title = "Heatmap de los tiros tomados en las temporadas 2009 y 2010") +
coord_cartesian(expand = FALSE)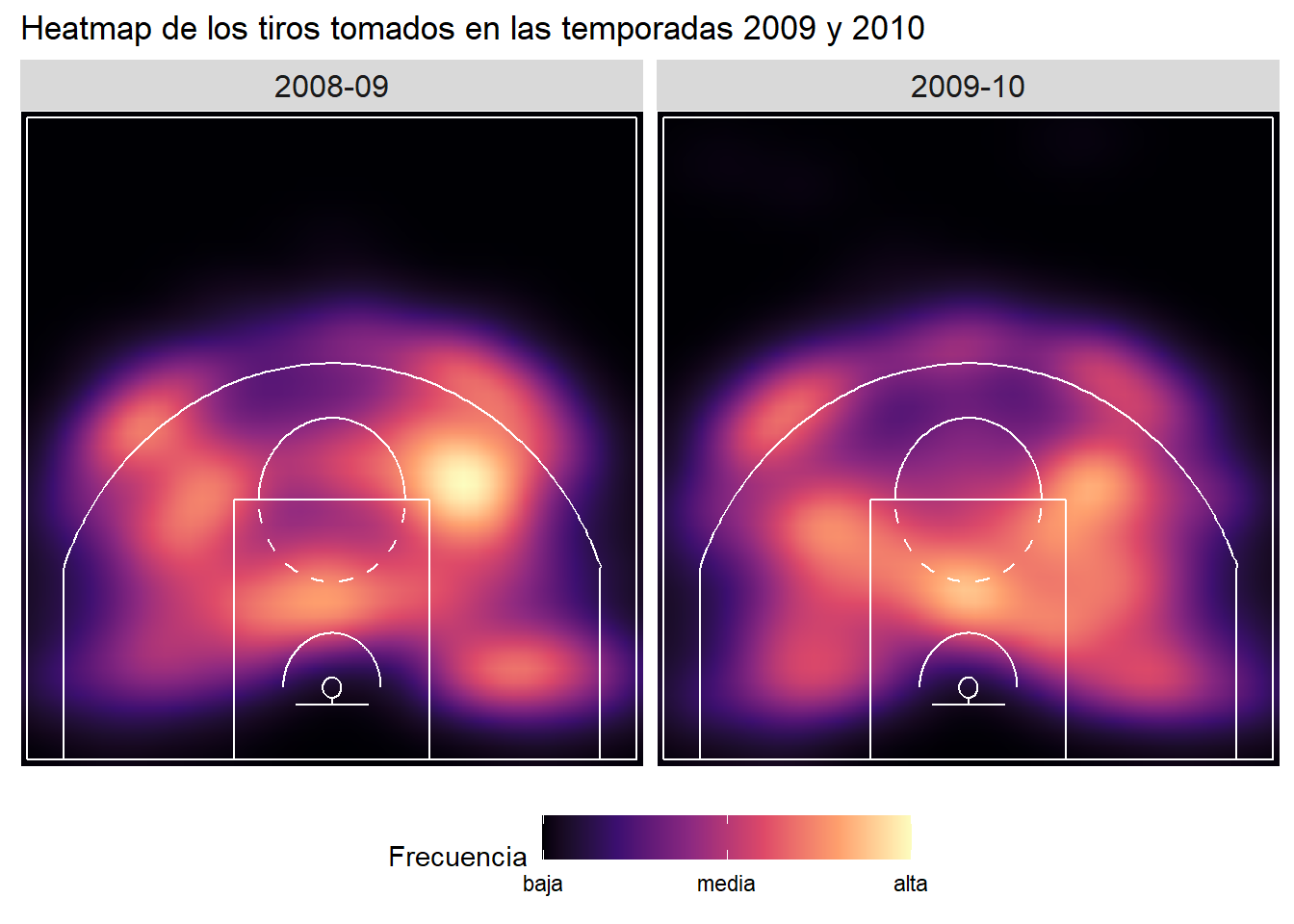
Un gráfico más, ahora con los trableritos y los ganchos. En estos gráficos queda claro que tomaba los ganchos desde el centro y los tableritos del lado derecho, el lado de su mano dominante.
shots_data %>%
filter(combined_shot_type %in% c("Bank Shot", "Hook Shot"), shot_zone_basic != "Backcourt") %>%
mutate(
combined_shot_type = factor(
combined_shot_type,
levels = c("Bank Shot", "Hook Shot"),
labels = c("Tableritos", "Ganchos"))
) %>%
ggplot() +
stat_density2d(
aes(x = loc_x,
y = loc_y,
fill = stat(density/ max(density))),
geom = "raster",
contour = FALSE,
interpolate = TRUE,
n = 50
) +
facet_wrap(~combined_shot_type, scales = "free") +
geom_path(
data = court_points,
aes(x = x, y = y, group = desc),
color = "white"
) +
scale_fill_viridis_c(
"Frecuencia de tiro",
limits = c(0, 1),
breaks = c(0, 1),
labels = c("baja", "alta"),
option = "magma",
guide = guide_colorbar(barwidth = 8)
) +
theme(
axis.text = element_blank(),
axis.title = element_blank(),
panel.grid = element_blank(),
axis.ticks = element_blank(),
panel.background = element_blank(),
strip.text = element_text(size = 12),
legend.position = "bottom"
) +
coord_cartesian(expand = FALSE)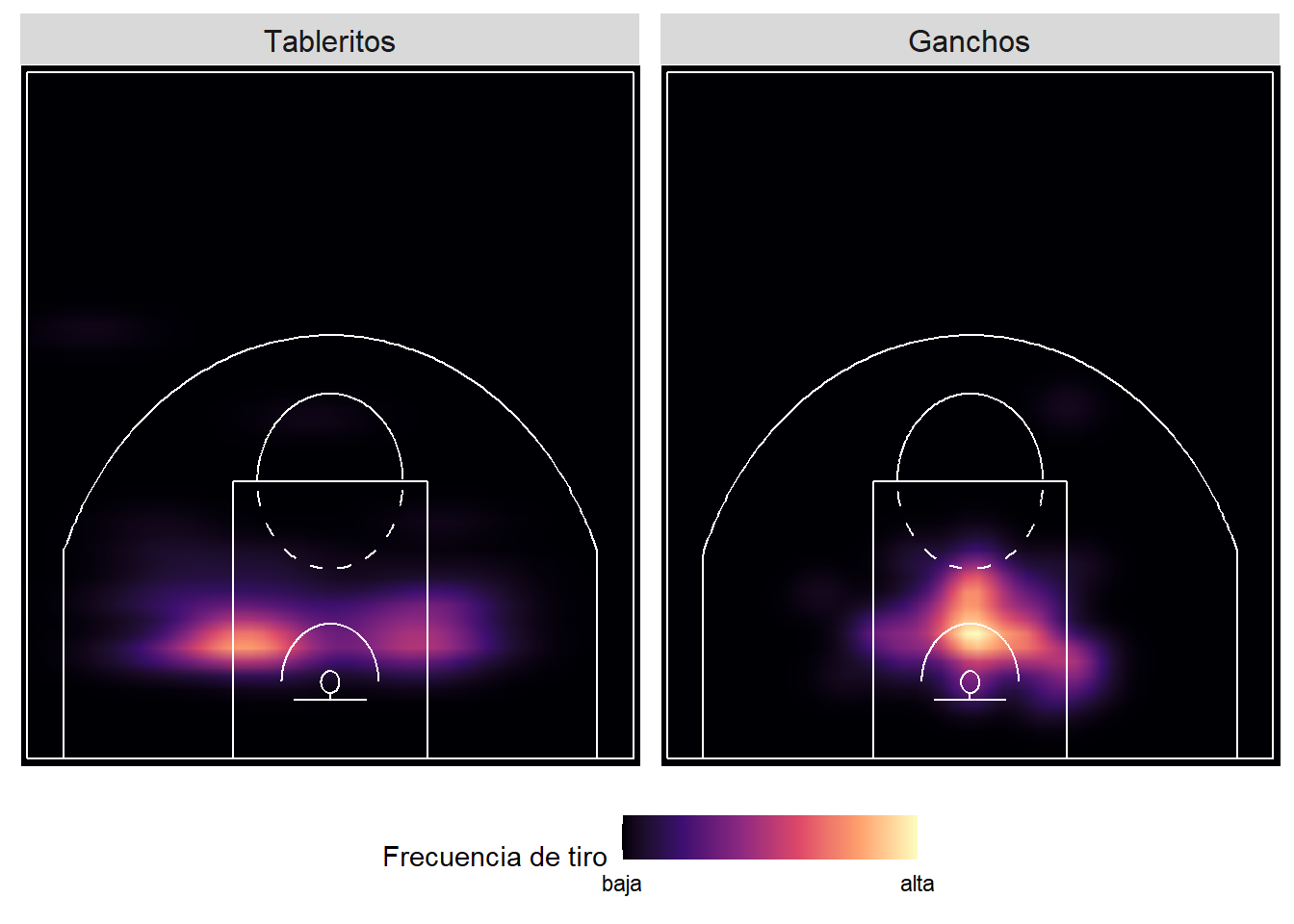
El tipo de tiro es una variable muy interesante y que sin dudas tendrán un protagonismo mayor a la hora de hacer el ejercicio de clasificación de los tiros para la competencia.
shots_data %>%
group_by(combined_shot_type) %>%
summarise(
cantidad = n(),
eficiencia = mean(shot_made_flag, na.rm = TRUE)
) %>% arrange(desc(cantidad))## # A tibble: 6 x 3
## combined_shot_type cantidad eficiencia
## <chr> <int> <dbl>
## 1 Jump Shot 23485 0.391
## 2 Layup 5448 0.565
## 3 Dunk 1286 0.928
## 4 Tip Shot 184 0.349
## 5 Hook Shot 153 0.535
## 6 Bank Shot 141 0.792Ahora unas cuantas visualizaciones de Kobe en el clutch. El siguiente gráfico analiza la cantidad de tiros que tomaba en cada minuto del último cuarto. No es de sorprender que al principio del último período tomara pocos tiros, porque normalmente a los estelares los descansan al principio para aprovecharlos al final del juego.
En el caso de Kobe, claramente, los últimos 6 minutos del último período eran para él, sobre todo el último minuto.
shots_data %>%
filter(period == 4) %>%
group_by(minutes_remaining) %>%
summarise(
tiros = n(),
eficiencia = mean(shot_made_flag, na.rm = TRUE)
) %>%
ggplot(aes(x = minutes_remaining, y = tiros)) +
geom_point(size = 4, color = "midnightblue") +
geom_text(aes(label = paste0(round(eficiencia*100, 1), "%"),
vjust = -1)) +
scale_x_reverse(breaks = 11:0) +
theme_minimal() +
coord_cartesian(ylim = c(300, 1000)) +
labs(x = "Minutos restantes",
y = "Cantidad de tiros",
title = "Tiros tomados en cada minutos del último cuarto y eficiencia",
subtitle = "Nadie tiraba más que Kobe en el clutch")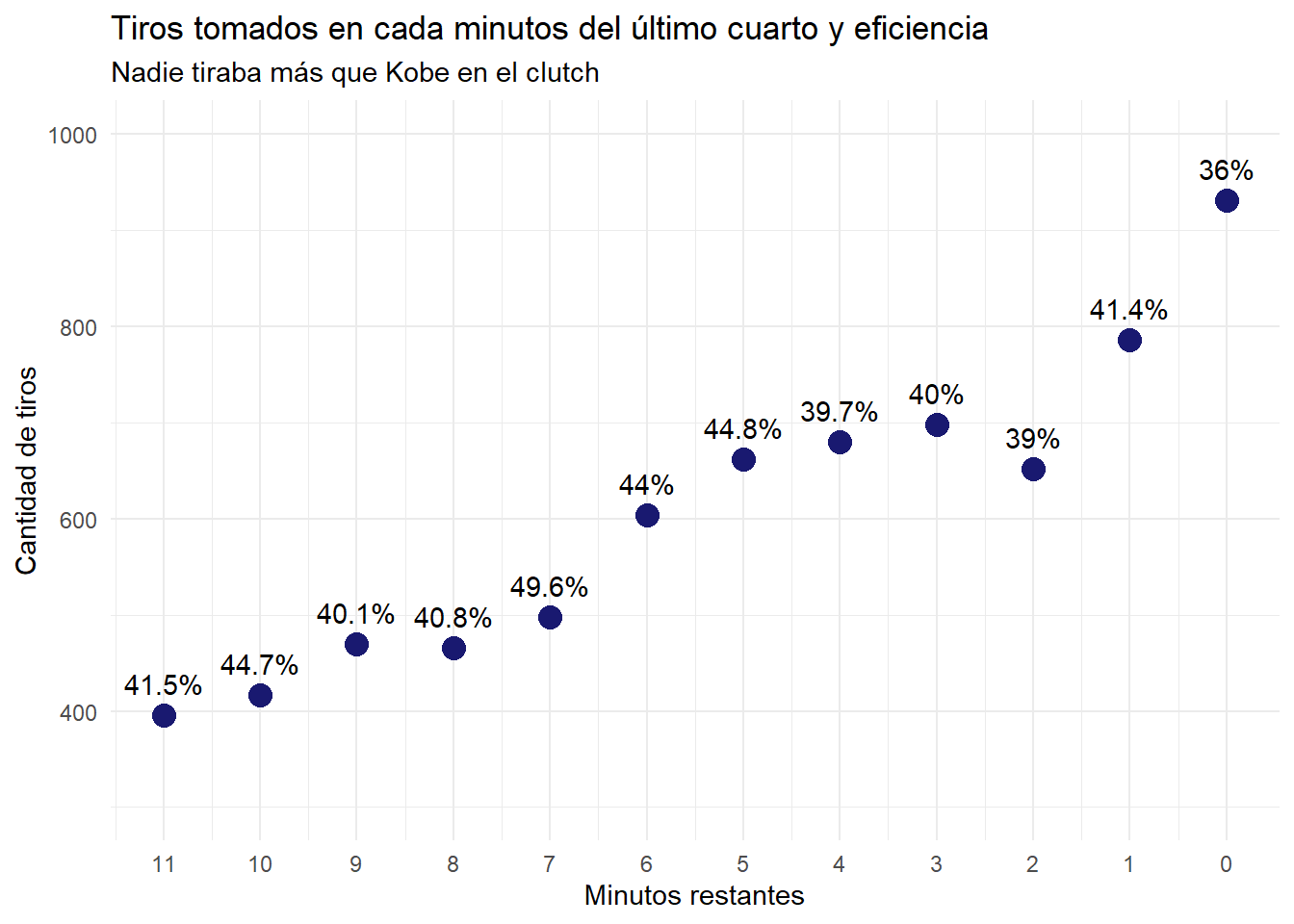
Comentarios finales
Con este básico análisis exploratorio se sientan las bases para modelar los tiros de Kobe y tratar de clasificar los 5,000 intentos que vienen con shot_made_flag missing. El próximo post de esta serie se enfocará en eso, entrenando dos modelos y comparando sus resultados.
Al ser la variable dependiente una variable categórica es probable que termine comparando desempeño de una regresión logística y el random forest para clasificación.
Como el Random Forest es una metología de machine learning poco explorada en la literatura nacional, ese post vendrá acompañado de una nota metológica.
Referencias
comments powered by Disqus