Recientemente terminé de leer el libro Forecasting: Principles and Practice de Rob J Hyndman y George Athanasopoulos y como es natural antes de elegir este material, y mientras lo leía, fui investigando sobre los autores, principalmente sobre Rob Hyndman. Este señor ha escrito una innumerable cantidad de papers útiles para aprender a modelar series temporales y ha desarrollado varios paquetes muy famosos para manejar series de tiempo en R.
Por suerte no me conformé simplemente con el contenido del libro y seguí investigando su trabajo, porque últimamente ha lanzado un serie de paquetes que transforma radicalmente la manera en la que se utilizan los objetos de series de tiempo en R, creando los paquetes tsibble, fable y feats que juntos conforman el tidyverts.
Como se pueden imaginar, el objetivo de esta serie de paquetes es hacer el manejo de las series de tiempo acorde a la filosofía del tidyverse y permitir que podamos utilizar muchas de las funciones que vienen en paquetes como dplyr, purrr, tidyr.
Siendo esto nuevo para muchas personas ahora mismo, quiero aprovechar la oportunidad y compartir un análisis de series temporales usando estas nuevas herramientas.
Manos a la obra
Paquetes
library(tidyverse) # manipulación, visualización de datos
library(forecast) # pronosticar series de tiempo
library(broom) # analizar resultados de modelos
library(tsibble) # crear series de tiempo tsibble
library(fable) # modelar series de tiempo tsibble
library(lubridate) # minipular objetos tipo dateLa data
En este ejercicio utilizaremos los datos de inflación y tipo de cambio publicados por el Banco Central de la República Dominicana.
Para obtener la data se pueden seguir dos vías vías:
- Descargar los archivos desde la página web del Banco, quitar las filas en blanco e innecesarias, limpiar los headers y manipular todas las variables para que queden listas para ser importadas y/o utilizadas. (Menciono todo esto porque es el contenido de una de mis próximas publicaciones, estaré mostrando como programar la descarga y limpieza de archivos desde la página del Banco Central)
- Usar los csv ya procesados para el ipc y el tipo de cambio que tengo en la nube (Esta es la forma recomendada).
Tras descargar los archivos los importamos con los nombres ipc y tc y los mutamos como se detalla a continuación.
# Filtrar y adecuar --- --- ---
# ipc --- ---
ipc <- ipc %>%
filter(fecha > "2010-12-31") %>%
select(-year, -mes) %>%
mutate(
fecha = yearmonth(fecha)
)
# Tipo de cambio --- ---
tc <- tc %>%
filter(fecha > "2010-12-31") %>%
mutate(
fecha = ym_fecha
)
# Data en formato "tidy" --- --- ---
# ipc --- ---
ipc_long <- ipc %>%
gather("variable", "variacion", -fecha) %>%
select(-ipc_vd) %>%
mutate(
variable = factor(
variable,
levels = c("ipc", "ipc_vm", "ipc_vi", "ipc_p12"),
labels = c("Índice","Variación mensual",
"Variación interanual", "Promedio 12 meses"))
)
#tipo de cambio --- ---
tc_long <- tc %>%
select(-year, -mes) %>%
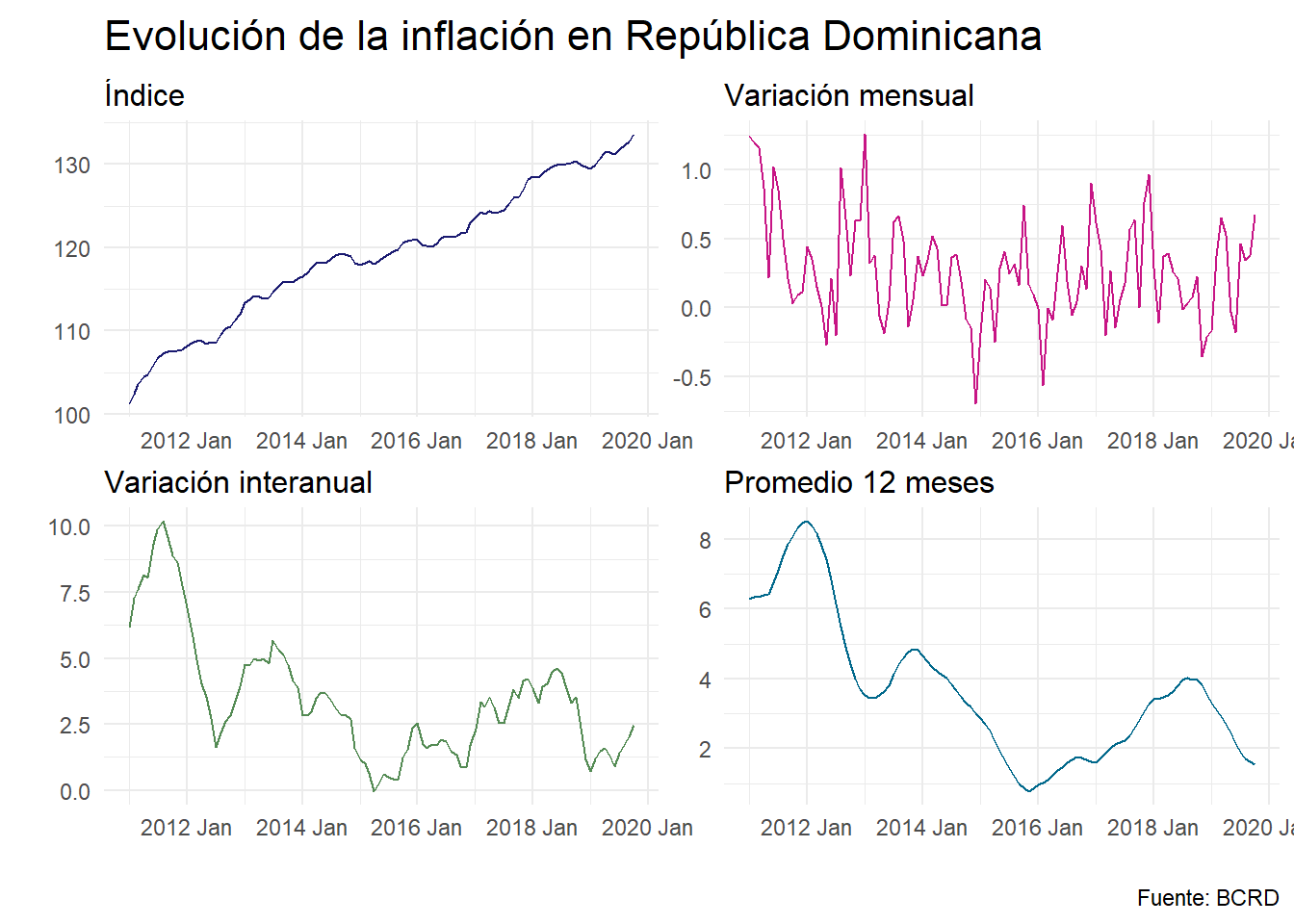
gather(key = "compra_venta", "tasa", -fecha)Podemos hacer un gráfico muy sencillo de los datos y ver como se comportó el IPC desde el 2011 a la fecha, observando la evolución del nivel del índice, las variaciones mensual, interanual y promedio de los últimos 12 meses.
# para los gráficos estaré usando una paleta definida por mí
my_color_pal <- scale_color_manual(
values = c("midnightblue", "mediumvioletred",
"palegreen4", "deepskyblue4")
)
# gráfico variación mensual e interanual
ipc_long %>%
ggplot(aes(x = fecha, y = variacion, color = variable)) +
geom_line(show.legend = FALSE) +
my_color_pal +
facet_wrap(~variable, scales = "free") +
labs(
x = "",
y = "",
title = "Evolución de la inflación en República Dominicana",
caption = "Fuente: BCRD"
)
Este gráfico y las modificaciones que le hicimos a los archivos no tienen nada de sorprendente, porque se tratan de tibbles o data.frame. Lo interesante empieza cuando hacemos este tipo de cosas a series de tiempo.
Creando, modificando y visualizando tsibbles
Ahora es cuando empieza la magia, vamos a crear un objeto tsibble a partir de los tibbles. Una de las primera ventajas que le veo a crear estos objetos es que no es necesario especificar la fecha de inicio y la periodicidad como cuando usamos la función ts(), aquí simplemente indicamos la variable que representará el tiempo (por definición esta variable deber ser tipo yearquarter, yearmonth, yearweek, date o POSIXt) y qué variable representa el key (en caso de que aplique).
Vamos a crear tsibble para cada uno de los dataframe que tenemos usando la función as_tsibble.
# tsibble del ipc
ipc_tsibble <- as_tsibble(
ipc, # data frame
index = fecha # variable con el tiempo
) %>%
fill_gaps()
ipc_long_tsibble <- as_tsibble(
ipc_long, # data frame
key = variable,
index = fecha # variable key
) %>%
fill_gaps()
# tsibble del tipo de cambio
tc_tsibble <- tc %>%
select(-year, -mes) %>%
as_tsibble(
index = fecha
)
tc_long_tsibble <- tc_long %>%
as_tsibble(
index = fecha,
key = compra_venta
)Para mostrar lo bien integrados que están los objetos tsibble con las funciones del tidyverse vamos a agregar algunas variables al tsibble del tipo de cambio y también haremos algunos gráficos usando ggplot2.
Las variables que vamos a agregar son la brecha del tipo de cambio de compra y venta, y las variaciones porcentuales mensuales de todas las variables existentes el este data set. Para esta acción usaremos mutate y mutate_at.
# Agregando la brecha de tasa al objeto de serie de tiempo
tc_tsibble <- tc_tsibble %>%
mutate(
brecha = tcn_venta - tcn_compra
)
# Agregando la variación porcentual
# de todas las variables
tc_tsibble <- tc_tsibble %>%
mutate_at(
.vars = vars(-fecha),
.funs = list(
var = ~ ((./lag(.))-1)*100
)
)Ahora hagamos un gráfico del tipo de cambio tal y como hicimos con la inflación, pero ahora usando los objetos de serie de tiempo.
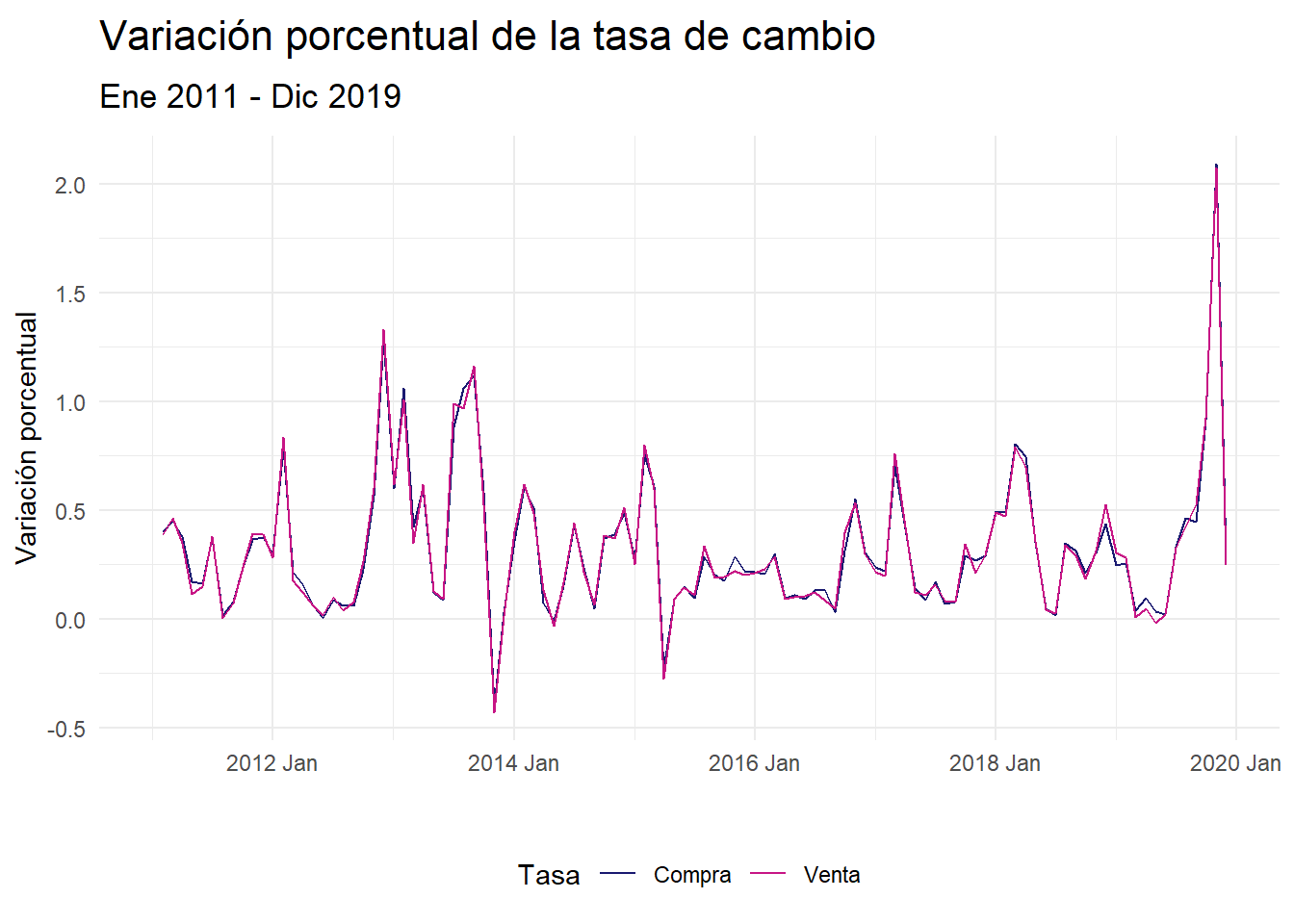
# Gráfico de las variaciones de las tasas
tc_tsibble %>%
ggplot() +
geom_line(aes(x = fecha, y = tcn_compra_var, color = "Compra")) +
geom_line(aes(x = fecha, y = tcn_venta_var, color = "Venta")) +
my_color_pal +
theme(legend.position = "bottom") +
labs(
x = "",
y = "Variación porcentual",
color = "Tasa",
title = "Variación porcentual de la tasa de cambio",
subtitle = "Ene 2011 - Dic 2019"
)
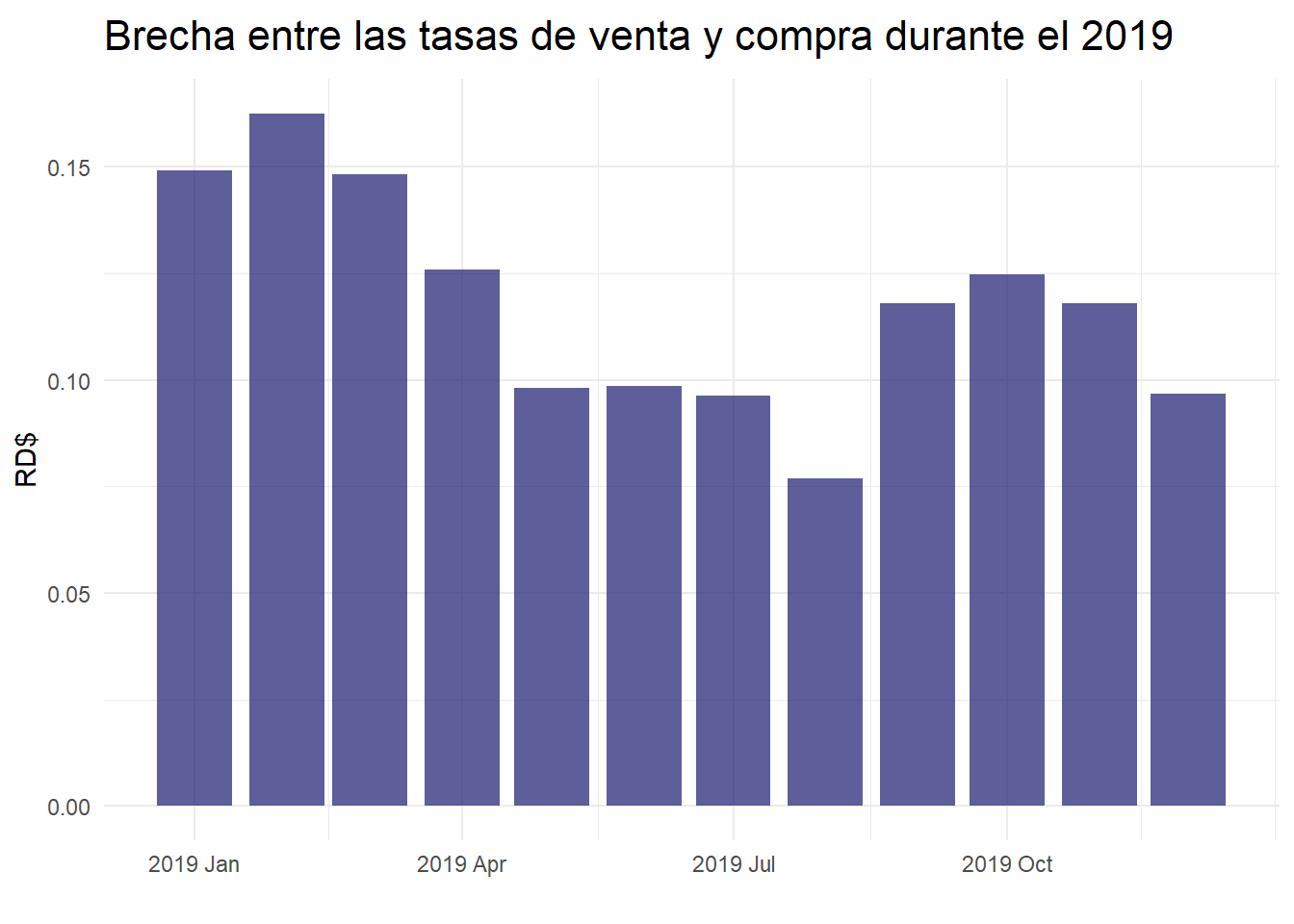
# gráfico de la brecha de tasas
tc_tsibble %>%
filter(fecha > "2018-12-01") %>%
ggplot(aes(x = fecha, y = brecha)) +
geom_col(show.legend = FALSE, fill = "midnightblue", alpha = 0.7) +
labs(
x = "",
y = "RD$",
title = "Brecha entre las tasas de venta y compra durante el 2019"
)
Un poco de forecasting
En esta ocasión estaremos realizando los pronósticos con la metodología Exponential smoothing (suavizamiento exponencial), que tiene la ventaja de ser muy intuitiva y permitir que la podamos describir sin desviarnos mucho del objetivo principal de la publicación que es mostrar cómo usar esta nueva estructura de datos propuesta por Hyndman. Igual, en publicaciones futuras sí prestaremos atención a los detalles metodológicos de las estrategias de forecasting.
Un pronóstico usando exponential smoothing es un promedio ponderado de las observaciones pasadas, en el que las observaciones más recientes tienen mayor peso y la ponderación disminuye de manera exponencial a medida que los registros se alejan del tiempo t. En este sentido, el parámetro común a estimar en todas las variantes existentes de esta metodología es el peso que tendrá la observación más reciente.
Dependiendo de la característica de la serie de tiempo a pronosticar se debe elegir entre métodos de suavizado exponencial que van desde versiones simples, en las que solo se estima el peso de la observación más recientes, a otros en los que además se estiman componentes como: tendencia (lineal o no), estacionalidad (aditiva o multiplicativa) y el tipo de intervalo de pronóstico.
Para elegir la variante adecuada de suavizamiento exponencial sin tener que detenernos a hacer pruebas específicas a la serie de tiempo, utilizaremos la función ETS() (Errors, Trend, Seasonal). Esta función se encarga de análizar las características de las series y aplicar la variante de smoothing que mejor le va.
Además del ets correremos un modelo ingenuo, que sirva de bechmark para el ets. Todos estos modelos los correremos en una sola llamada a la función model(), la cual recibe como argumentos un tsibble y la declaración de los modelos que nos interesan.
fit_ipc_vm <- ipc_tsibble %>%
select(ipc_vm) %>%
fabletools::model(
ets = ETS(ipc_vm),
naive = NAIVE(ipc_vm)
)
fit_ipc_long <- ipc_long_tsibble %>% model(
ets = ETS(variacion),
naive = NAIVE(variacion)
)
fit_ipc_long## # A mable: 4 x 3
## # Key: variable [4]
## variable ets naive
## <fct> <model> <model>
## 1 Índice <ETS(A,A,N)> <NAIVE>
## 2 Variación mensual <ETS(A,Ad,N)> <NAIVE>
## 3 Variación interanual <ETS(A,Ad,N)> <NAIVE>
## 4 Promedio 12 meses <ETS(A,Ad,N)> <NAIVE>Este resultado es un mable o tabla de modelos, en la que en cada columna tenemos una metodología y en cada fila una serie distinta. En el caso del data set ipc_long_tsibble hay un key con 4 variables, por eso el resultado fit_ipc_long tiene cuatro filas.
Para explorar los detalles del modelo empleado para alguno de los key podemos usar ejecutar el siguiente comando.
fit_ipc_long %>%
filter(variable == "Variación mensual") %>%
select(ets) %>%
report()## Series: variacion
## Model: ETS(A,Ad,N)
## Smoothing parameters:
## alpha = 0.005901614
## beta = 0.0006940318
## phi = 0.8
##
## Initial states:
## l[0] b[0]
## 1.902121 -0.4207946
##
## sigma^2: 0.1176
##
## AIC AICc BIC
## 274.3390 275.1874 290.3196Para el caso de la variación mensual del índice, la función especificó un modelo con errores aditivos, y sin estacionalidad.
Ahora vamos a hacer el forecast de cada variable para los próximos 12 períodos.
fc_ipc_vm <- fit_ipc_vm %>%
fabletools::forecast(h = 12)
fc_ipc_long <- fit_ipc_long %>%
fabletools::forecast(h = 12)
fc_ipc_long## # A fable: 96 x 5 [1M]
## # Key: variable, .model [8]
## variable .model fecha variacion .mean
## <fct> <chr> <mth> <dist> <dbl>
## 1 Índice ets 2019 Nov N(134, 0.18) 134.
## 2 Índice ets 2019 Dec N(135, 0.51) 135.
## 3 Índice ets 2020 Jan N(135, 1) 135.
## 4 Índice ets 2020 Feb N(136, 1.8) 136.
## 5 Índice ets 2020 Mar N(136, 2.9) 136.
## 6 Índice ets 2020 Apr N(137, 4.2) 137.
## 7 Índice ets 2020 May N(138, 6) 138.
## 8 Índice ets 2020 Jun N(138, 8.2) 138.
## 9 Índice ets 2020 Jul N(139, 11) 139.
## 10 Índice ets 2020 Aug N(139, 14) 139.
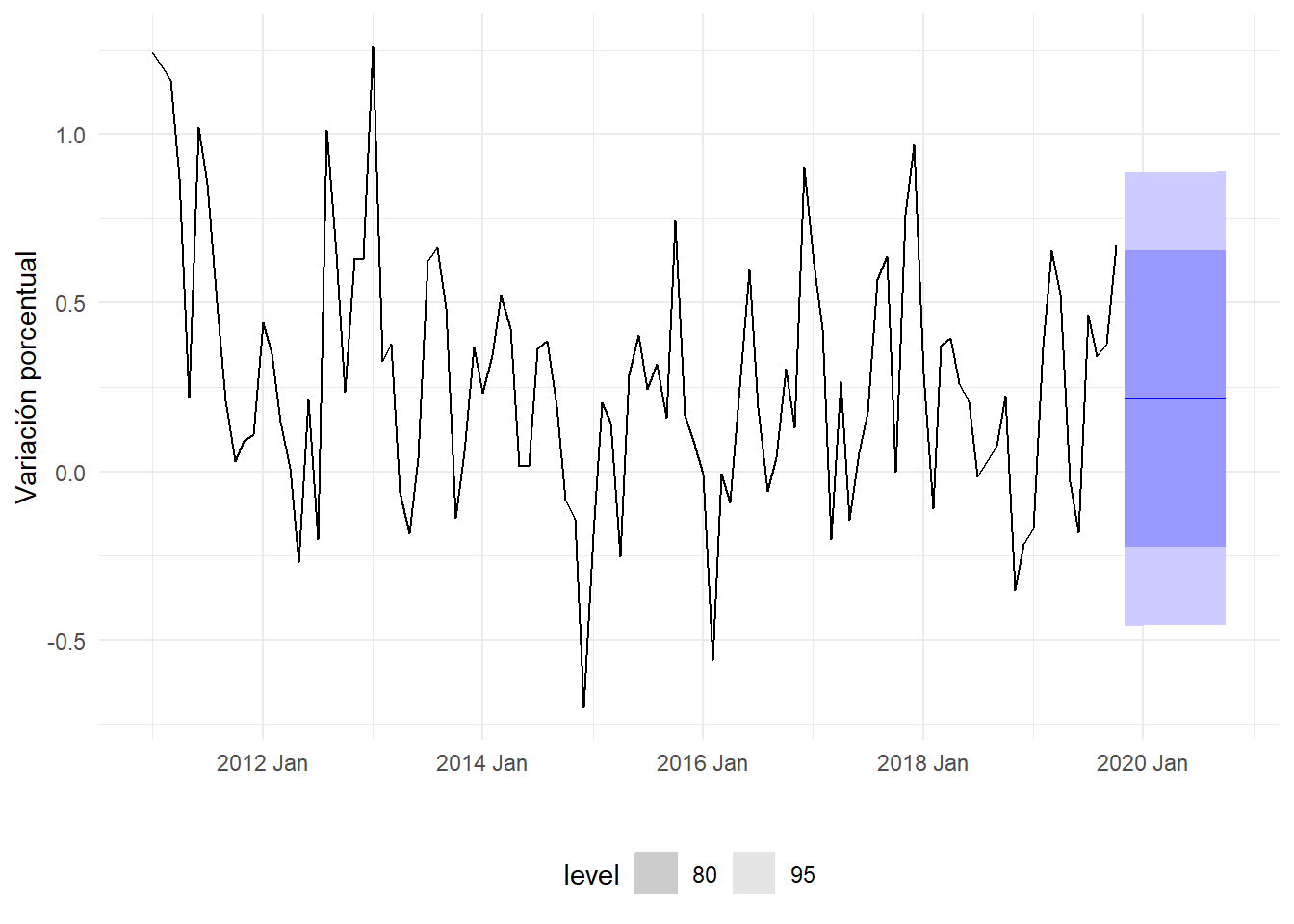
## # ... with 86 more rowsAhora vamos a visualizar el resultado del forecast pero en un gráfico.
fc_ipc_vm %>%
filter(.model == "ets") %>%
autoplot(ipc_tsibble %>% select(ipc_vm)) +
theme(legend.position = "bottom") +
labs(
x = "",
y = "Variación porcentual"
) 
Con esto logramos el objetivo de introducir las nuevas estructura de datos que ofrece el tidyverts, sin dudas una gran innovación por parte del grupo de desarrolladores de este paquete. En otras publicaciones pretendo mostrar ejercicios más con complejos, en las que explique con más detalles el método de suavizado exponencial y otros.
comments powered by Disqus