Cuando me topé por primera vez con las funciones del tidyverse, específicamente con el paquete dplyr, lo que más me atrajo fue la posibilidad de usar en las funciones las variables in-data como si fueran objetos del ambiente global (data masking).
Es como utilizar en un data frame el poco recomendado attach(), pero sin el downside que deriva este en distintos escenarios.
Un ejemplo:
mtcars[mtcars$cyl == 8 & mtcars$am == 1,]## mpg cyl disp hp drat wt qsec vs am gear carb
## Ford Pantera L 15.8 8 351 264 4.22 3.17 14.5 0 1 5 4
## Maserati Bora 15.0 8 301 335 3.54 3.57 14.6 0 1 5 8filter(mtcars, cyl == 8, am == 1)## mpg cyl disp hp drat wt qsec vs am gear carb
## Ford Pantera L 15.8 8 351 264 4.22 3.17 14.5 0 1 5 4
## Maserati Bora 15.0 8 301 335 3.54 3.57 14.6 0 1 5 8# Opción que muchos nuevos usuarios intentan, por parecer intuitivo
# pero que sin excepciones conduce a un error
# mtcars[cyl == 8, am == 1]En el primer ejemplo hubo que escribir el nombre del set de datos 3 veces, mientras que con la función dplyr::filter() solo una vez.
Esto se logra gracias al data masking que usan las funciones del tidyverse, el cual es muy conveniente, sobre todo en niveles iniciales, porque evita algunas confusiones y permite hacer ciertas tareas con menos código.
Ahora bien, en la medida que uno va avanzando se encuentra con el amargo sabor de que lo que nos facilitaba la vida del tidyverse se convierte en una dificultad a la hora de programar con él.
Recuerdo hace unos años cuando intenté hacer mis primeras funciones que involucraban el tidyverse. En ese entonces los verbos paralelos del paquete no habían sido abandonados, aún se recomendaba el uso de mutate_(), mutate_at(), group_by_(), group_by_at(), summarise_at() y unas tantas otras (En las versiones más recientes se han integrado otras funciones que evitan la necesidad recurrir a todas estas funciones gemelas del tidyverse, no es necesario que se preocupen por aprender a usarlas).
Teniendo en cuesta esto, esta vez pretendo hacer una breve explicación de como crear funciones que aprovechen el data masking del tidyvers y que aplanen el camino para aquellos que pretenden crear paquetes con {dplyr}, {ggplot2} y otros como dependencias. También para aquellos que van a utilizar shiny y necesitarán crear funciones que reciban el nombre de las variables en forma de strings como argumento (los imputs de shiny normalmente devuelven valores de este tipo).
En fin, para que no intenten hacer esto:
error1 <- function(variable = cyl) {
mtcars %>%
group_by(variable) %>%
summarise(mean_mpg = mean(mpg))
}
error2 <- function(variable = 'cyl') {
mtcars %>%
group_by(variable) %>%
summarise(mean_mpg = mean(mpg))
}Variables de ambiente, variables en data y data masking
La idea principal del data masking es estrechar la brecha entre las dos vertientes de variables que pueden existir en R. Por un lado las variables de ambiente y por otro las variables en data.
Las variables de ambiente son esos objetos que residen en el ambiente global de nuestra sesión de trabajo y que normalmente son creados usando el operador de asignación <-.
Las variables en data son aquellas variables que residen dentro de un objeto del ambiente global, como un data frame (U otros tipos de lista) y a ellas se accede usando operadores como $ y la notación de corchetes [ o [[.
Para poner un ejemplo, el siguiente fragmento de código crea una variable de ambiente que contiene a su vez dos variables en data.
personas <- data.frame(
nombre = c("Johan", "Fulano"),
ead = c(28, 32)
)
personas$nombre## [1] "Johan" "Fulano"El objeto personas es una variable de ambiente, reside en el ambiente global, mientras que nombre y edad son variables en data, contenidas en personas. Cuando se usan las funciones con data masking se disuelve un poco la diferencia entre estos objetos, pero en general es importante tenerlo en cuenta antes de ir un paso más lejos en la programación en R.
Usando el embracing {{ variable }} y el pronombre .data[[ "variable" ]]
El embracing es la primera alternativa que nos provee el tidyverse para programar usando funciones que utilizan data masking. Con esto se abre la posibilidad de generar referencias indirectas en las funciones.
La primera demostración consiste en crear una función que recibiendo un data frame y el nombre de las variables a mapear en cada eje, cree un scatter plot.
En este caso hay que prestar atención a la forma que se usan los argumentos en el cuerpo de la función, siempre se encierran entre un par de llaves {{ argumento }} y así se pasa el nombre de las variables en data como si fueran variables de ambiente en nuestras funciones.
scatter_plot <- function(data, x, y, color = NULL) {
ggplot2::ggplot(data = data, ggplot2::aes(x = {{ x }}, y = {{ y }}, color = {{ color }})) +
ggplot2::geom_point() +
ggplot2::theme_minimal() +
ggplot2::theme(legend.position = "bottom")
}
# Ya tenemos una función que usa data masking
scatter_plot(mtcars, x = wt, y = mpg, color = am)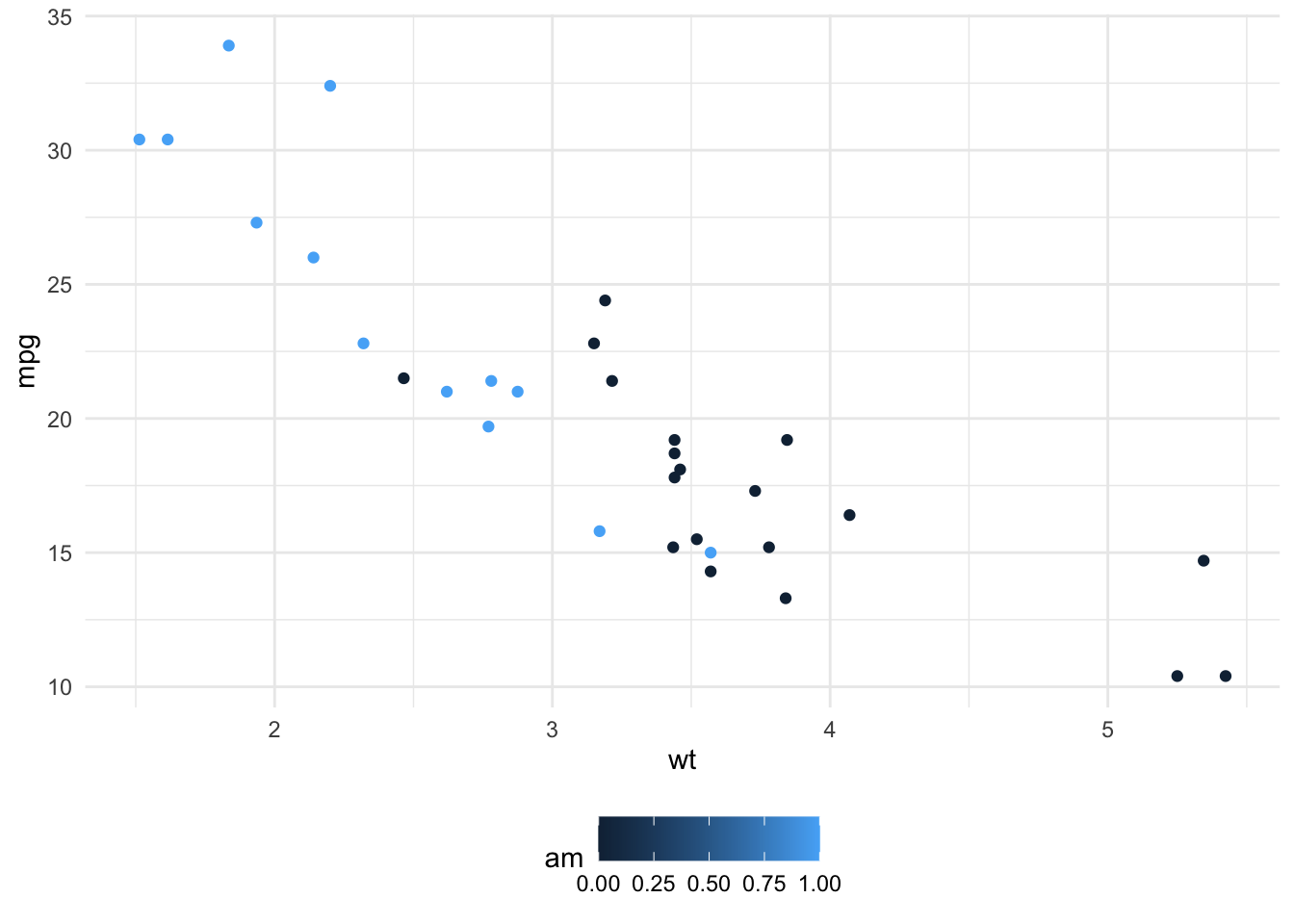
scatter_plot(data = iris, x = Sepal.Width, y = Sepal.Length, color = Species)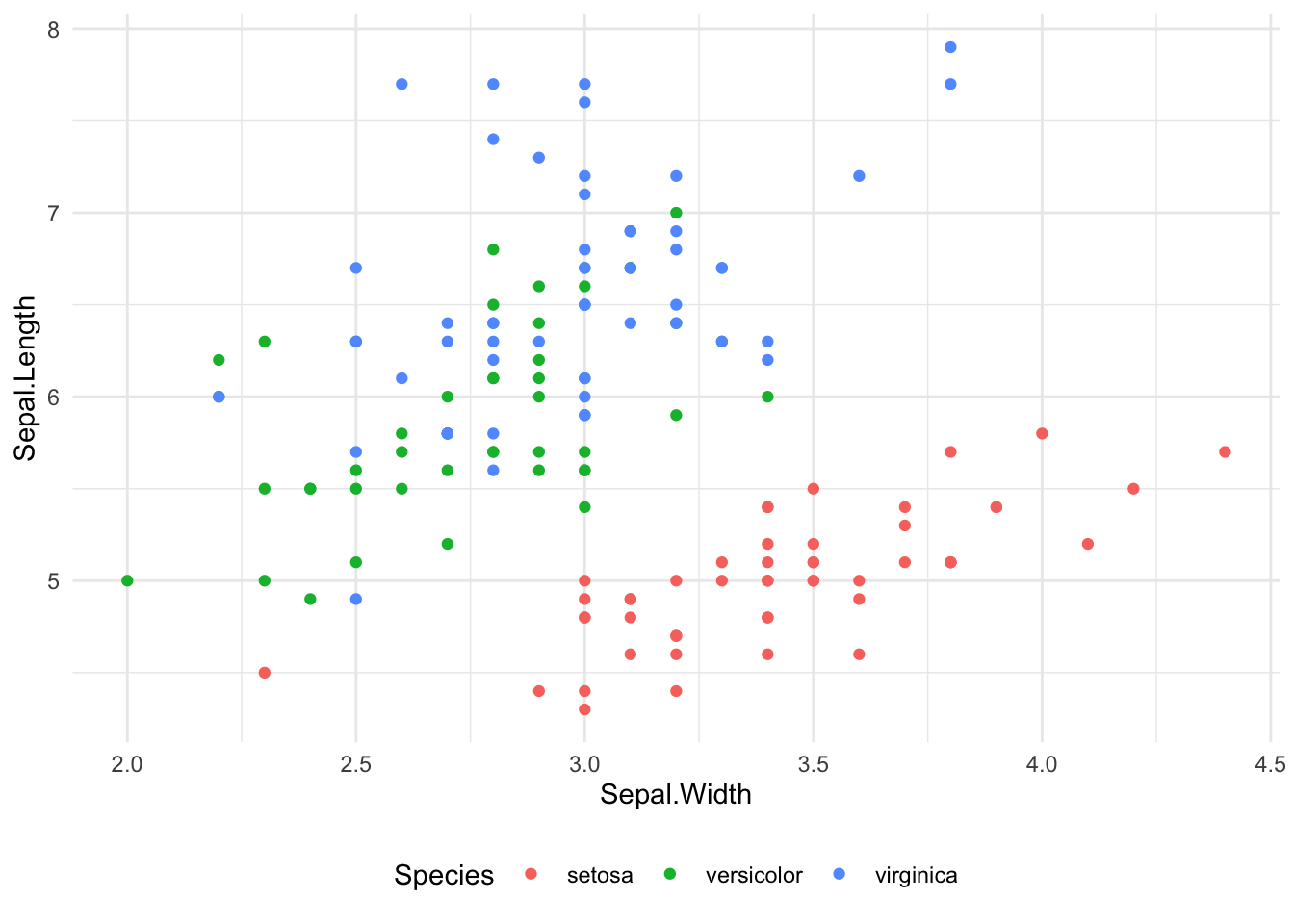
Otro recurso a nuestra disposición cuando se desea pasar strings con los nombres de las variables es el pronombre .data[[]].
Para usar esta alternativa creemos una función que devuelva el promedio de la variables que se le indique.
calc_media <- function(data, variable) {
dplyr::summarise(data, promedio = mean(.data[[variable]]))
}
calc_media(mtcars, variable = "mpg")## promedio
## 1 20.09062Esto no solo funciona en el scope de las funciones, en el ambiente global se podría utilizar también. Consideren el siguiente ejemplo de un loop:
for (variable in c("mpg", "wt", "hp")) {
dplyr::summarise(mtcars, media = mean(.data[[variable]])) %>% print()
}Programando con tidy selection
Algo muy distinto al data masking pero igual de útil es el tidy selection, que es una herramienta complementaria del tidyverse que facilita trabajar con más de una variable de manera simultánea.
Es probable que en este punto ya hayan utilizado las funciones starts_with(), ends_with(), where(), everything() dentro de la función select() o en la recién introducida across().
# Selecciona las variables que inician con 'sepal'
select(iris, starts_with("sepal")) %>%
head(3)
# revuelve el promedio de las variables que inician con "petal"
dplyr::summarise(iris, across(starts_with('petal'), mean))El punto es que estas funciones de asistencia del tidyselect se pueden aprovechar en nuestras funciones, abriendo un mundo de posibilidades para el usuario.
A continuación un ejemplo simple pero poderoso, una función que recibe sentencias de tidy selection como argumento y funciones para resumir dichas columnas. Para esto se hace uso de la función all_of().
my_summary <- function(data, cols = NULL, fun = mean) {
dplyr::summarise(
data,
dplyr::across(
.cols = all_of(cols),
.fns = fun
)
)
}A continuación ponemos a prueba la función, demostando su flexibilidad y conveniencia.
my_summary(iris, cols = starts_with("petal"), fun = sd)## Petal.Length Petal.Width
## 1 1.765298 0.7622377my_summary(mtcars, cols = c("mpg", "wt"), fun = median)## mpg wt
## 1 19.2 3.325Usando lo aprendido para crear una aplicación en shiny
Normalmente los inputs en las aplicaciones creadas con shiny general objetos que contienen números y caracteres para ser utilizados en el servidor y controlar los objetos reactivos de nuestra aplicación.
En este ejemple crearemos un shinyApp que permita construir un gráfico de dispersión con las variables del set de datos mtcars. La idea es que el usuario controle las variable que serán mapeadas a los ejes y al color de los puntos.
El primer paso es ajustar un poco la función para crear gráficos de dispersión que creamos anteriormente, para que en lugar de funiconar con data masking, reciba strings con los nombres de las variables.
shiny_scatter_plot <- function(data, x, y, color = NULL) {
ggplot2::ggplot(
data = data,
ggplot2::aes(x = .data[[x]], y = .data[[y]], color = as.factor(.data[[color]]))) +
ggplot2::geom_point() +
ggplot2::theme_minimal() +
ggplot2::theme(legend.position = "bottom") +
labs(color = color)
}Con esto se puede entonces crear la aplicación. No entraremos en detalles de cada componente en esta ocasión, pero queda el compromiso implicito de hacer un post sobre este tema. Esta vez la intención es mostrar una aplicación rápida de lo explicado.
library(shiny)
library(dplyr)
library(ggplot2)
ui <- fluidPage(
# Un título
h1("Explorando la base mtcars"),
# Layout del app
sidebarLayout(
sidebarPanel = sidebarPanel(
# Inputs para seleccionar variables de cada eje
selectInput(inputId = "x", label = "Variable del eje X",
choices = c("mpg", "disp", "hp", "draft", "qsec", "wt"),
selected = "wt",
multiple = FALSE),
selectInput(inputId = "y", label = "Variable del eje Y",
choices = c("mpg", "disp", "hp", "draft", "qsec", "wt"),
selected = "mpg",
multiple = FALSE),
selectInput(inputId = "color", label = "Variable color",
choices = c("cyl", "am", "vs", "gear", "carb"),
selected = "cyl", multiple = FALSE)
),
mainPanel = mainPanel(
# Output a mostra
h2(textOutput("title")),
plotOutput("plot")
)
)
)
server <- function(input, output, session) {
# El título del gráfico
output$title <- renderText(paste("mtcars:", input$x, "Vs", input$y))
# Usando los inputs para generar el gráfico
output$plot <- renderPlot({
# Usando nuestra función
shiny_scatter_plot(mtcars, x = input$x, y = input$y, color = input$color)
})
}
shinyApp(ui, server)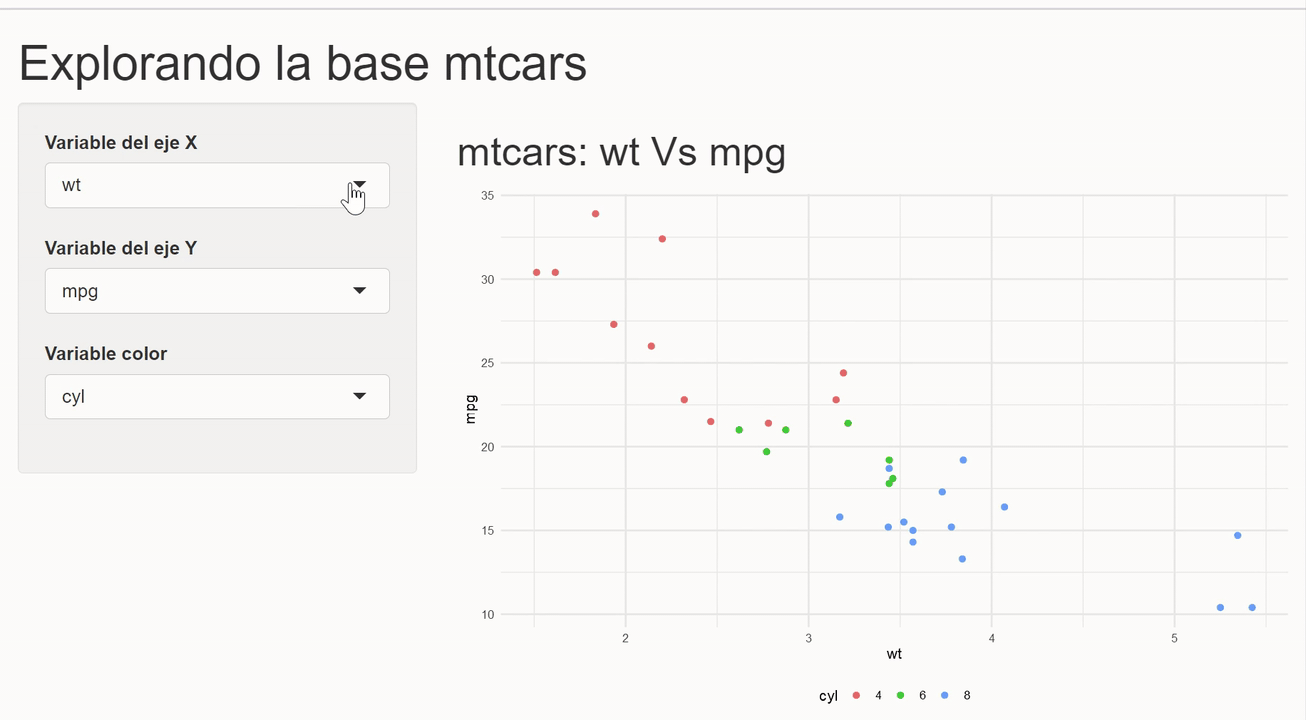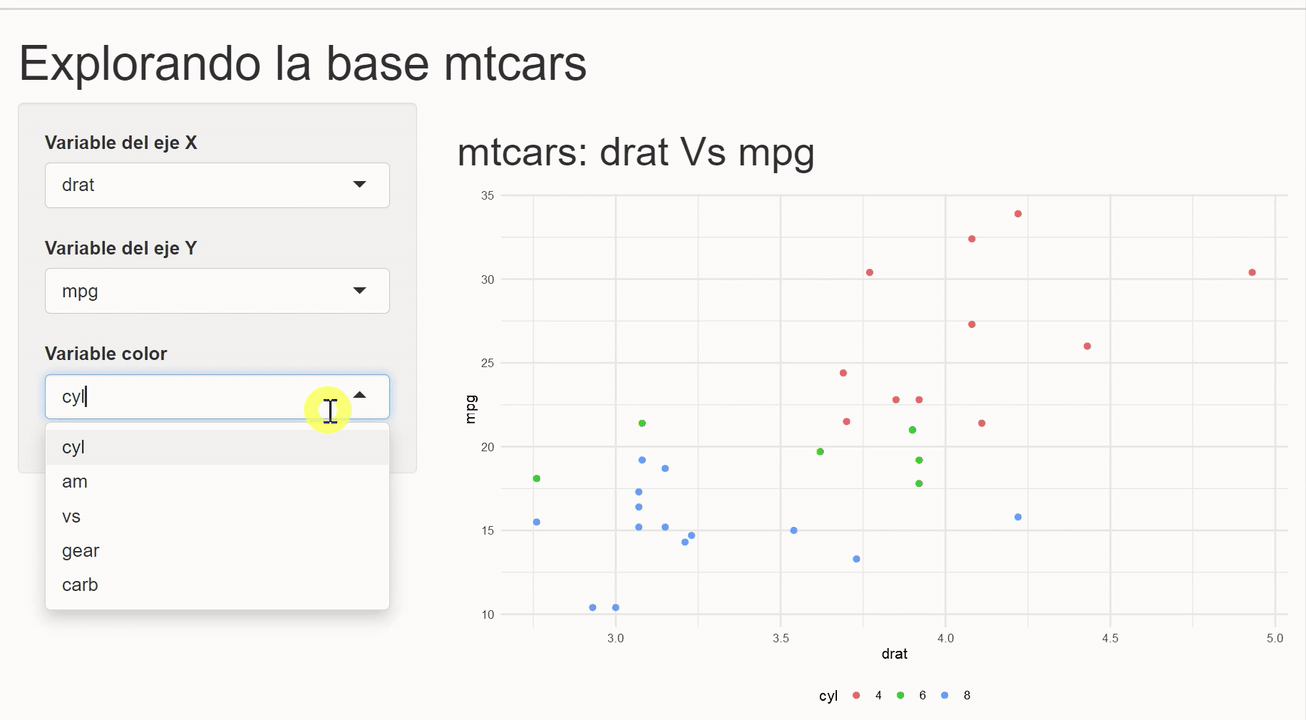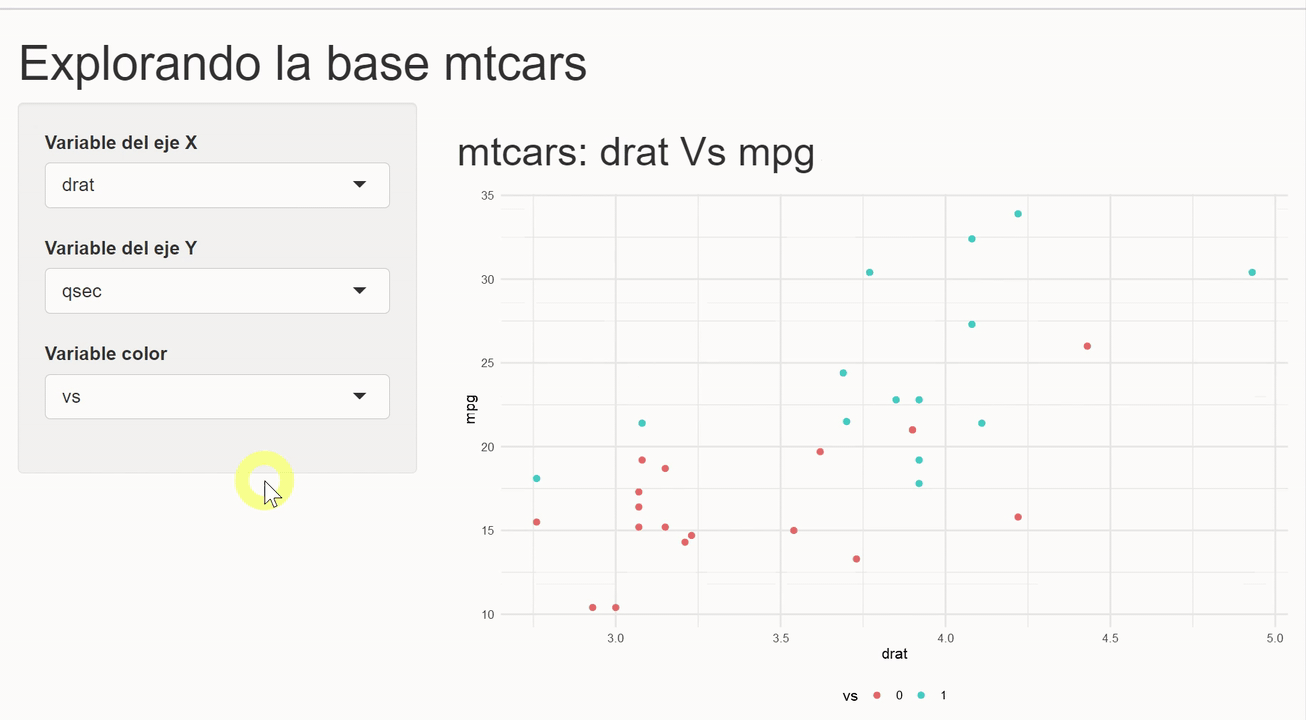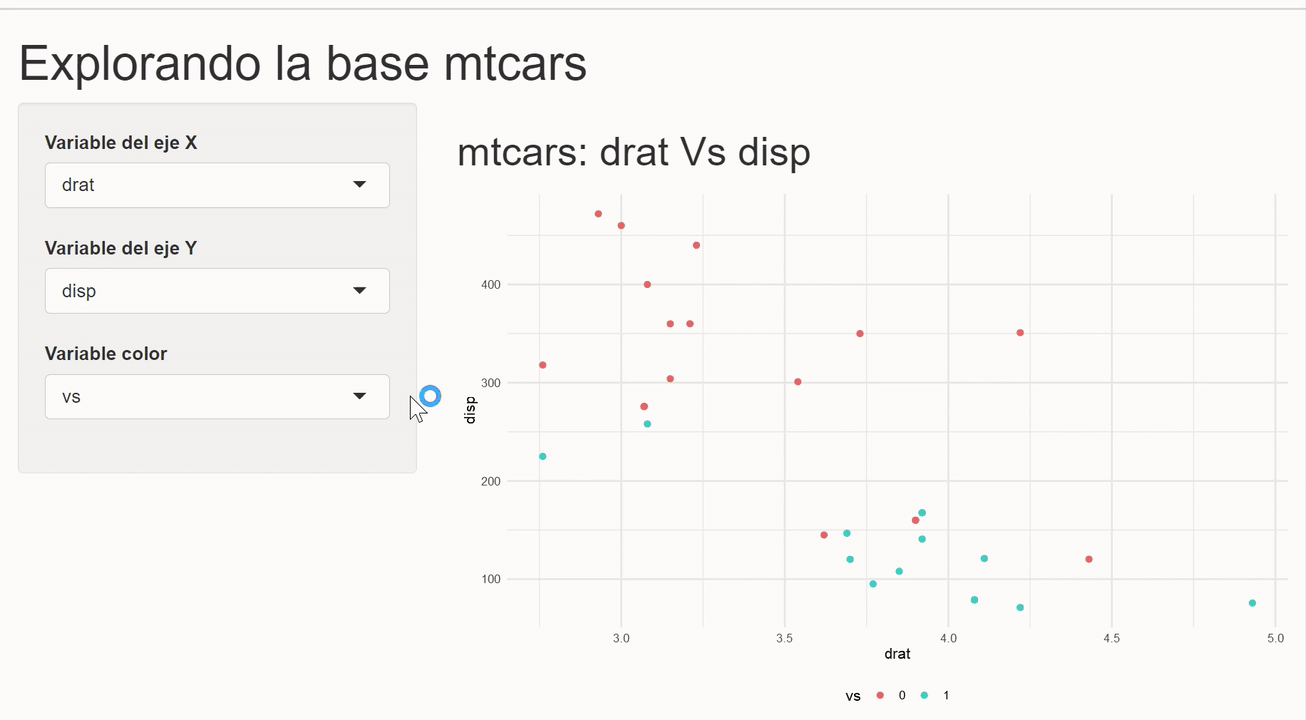
Consideraciones finales
No es lo mismo ser un usuario de R que un programador en R. Es importante comprender muy bien la estructura del leguaje y los objetos para ser programador, hay que dominar las clases, métodos, expreciones y muchos conceptos abstractos pero al final de cuentas vale la pena.
Yo empecé este trayecto con el libro de R avanzado de Hadley Wickhan, que da un paseo bastante detallado desde los aspectos más básicos como los atributos de los distintos tipos de objetos, hasta el metaprogramming.
Una vez avanzado este libro es importante empezar a leer R packages, y así aplicar lo aprendido en el desarrollo de paquetes propios.
comments powered by Disqus