kobe %>% as.legend('forever')
Esta semana recibí una de las noticias más impactantes de los últimos años, la trágica muerte de Kobe Bryant. Los que me conocen saben lo seguidor que soy de Kobe, siempre me he declarado su fanático, casi al extremo del término. Gran parte de mi niñez, toda mi adolescencia y ahora mi vida de adulto me la pasé viendo sus juegos, revisando sus jugadas, tratando imitar lo que hacía, discutiendo con mi hermano a ver quién se quedaría con el honor de decir que era él, comentando sus entrevistas, defendiendo su posición como top 2 histórico, etc.
La muerte de Kobe me afectó mucho y, siendo honesto, no me imaginaba tan susceptible al fallecimiento de alguien que no sea mi familiar. Pero como me dijo Cinthia al hablar al respecto: “Es el costo de las relaciones parasociales, Kobe no era una figura más para ti, era algo más significativo. Además, lo inesperado duele más”.
Hoy quiero honrar su memoria de la forma que mejor lo puedo hacer en este espacio, haciendo un análisis que instruya y que lo involucre. En general tengo pensando varias publicaciones como esta, pero la primera será una explicación de Componente Principales y usar la técnica en una imagen suya.
Reducción de dimensionalidad: Análisis de Componentes Principales
El análisis de componente principales (PCA) es una técnica de reducción de dimensionalidad muy útil, que permite resumir un conjunto de variables en pocas componentes y mantener la mayor proporción de la información (varianza) del set de datos original.
En general podríamos pensar en el problema imaginando jugadores de Basket, a cada jugador podríamos describirlo usando una serie de características como su estatura, la posición, la cantidad de juegos por temporada que juega o minutos por juego, puntos por partido, asistencias, etc. El que ha visto las estadísticas de los jugadores sabe que un set de datos puede tener muchas variables y, en este caso, el objetivo del análisis de componentes principales sería crear nuevas características basada en transformaciones lineales de las originales que ayuden a “resumir bien” las características de todos los jugadores.
Cuando hablamos de resumir bien en términos de esta metodología, nos referimos a que debemos terminar dándole mayor importancia a las características que contienen mayor información (mayor varianza) para distinguir los jugadores. Porque terminar con una nueva variable (Componente) construida con variables que no cambian mucho de jugador a jugador sería un tanto inútil, pues al final nuestra nueva característica nos dice que los jugadores son iguales a pesar de que sabemos que son muy distintos.
Por otro lado, otra cuestión a la que nos referimos al decir que las nuevas componentes deben resumir bien el set de datos es a que las componentes resultantes deben permitir la reconstrucción de la data original (minimizar los errores). Otra vez, sería inútil terminar con un resumen de las características de los jugadores que no permita terminar con una aproximación aceptable de la data que teníamos al principio.
Este último elemento es primordial para el ejercicio de este post, ya que la idea central aquí es ver cómo podemos reducir la dimensionalidad de la imagen y aun así terminar con una representación útil de la imagen original.
Para no diluir mucho la explicación, presentaremos bullets con las características principales de la técnica:
Las componentes principales son parte de la estructura subyacente de la data y señalan las direcciones en la que el conjunto de datos concentra mayor variabilidad (Piensen en un celular en posición vertical, ese teléfono podríamos observarlo desde arriba y no veríamos mucho de él, porque ese lado contiene poca información -varianza- o lo podemos ver por atrás y darnos cuenta de que tiene 3 cámaras y una manzanita dibujada y que se trata del Iphone 11 Pro).
Es probable que terminemos con varias componentes principales, pero nunca más componentes que variables en el set de datos original.
Cada componente principal adicional explica menos varianza que las anteriores.
Las componentes principales son ortogonales entre sí,es decir, que no están correlacionadas entre ellas.
Variables muy correlacionadas en el set de datos tienden a contribuir fuertemente a la misma componente principal.
Para ampliar un poco el entendimiento de la metodología recomiendo dos fuentes en particular, primero un post en Cross Validated que leí hace un tiempo y me ayudó a comprender la intuición detrás de esta técnica, y el manual de Lindsay I Smith que, con más formalidad matemática, explica la técnica e introduce la importancia del análisis de componentes principales para la compresión de imágenes.
Paquetes
# Manipulación y visualización
library(tidyverse)
# Manipular imágenes
library(imager)
# Manipular output de modelos
library(broom)Importando la imagen de Kobe y adecuándola para el análisis
Es importante prestar atención a esta parte del análisis ya que en cierta forma este representa el prerrequisito para algunos temas que trataremos más adelante en este blog. El procesamiento de imágenes está en la palestra y antes de hacer deep learning y reconocimiento de imágenes primero hay que importar las imágenes y saber cómo el software las maneja.
La imagen con la que trabajaremos la encontré en google imágenes, pueden acceder a todos los archivos en el repositorio del post en mi cuenta de github.
Usaremos la función load.image() para importar la imagen en un objeto tipo cimg.
kobe_img <- load.image("kobe_bw.jpg")Para obtener la información básica de la imagen simplemente hacemos print al objeto
print(kobe_img)## Image. Width: 640 pix Height: 360 pix Depth: 1 Colour channels: 3La imagen tiene 640 pixeles de ancho y 360 pixeles de alto, con tres canales. El hecho que tenga tres canales significa que la imagen no está completamente en escala de grises, y tienen valores en la escala de Rojos, Verdes y Azules(RGB). En ese caso usaremos la función grayscale() para llevarlo a la escala adecuada y poder cumplir con mayor facilidad el objetivo
# Cambiando a escala de grises
kobe_img <- grayscale(kobe_img)
# Consultando otra vez las dimensiones
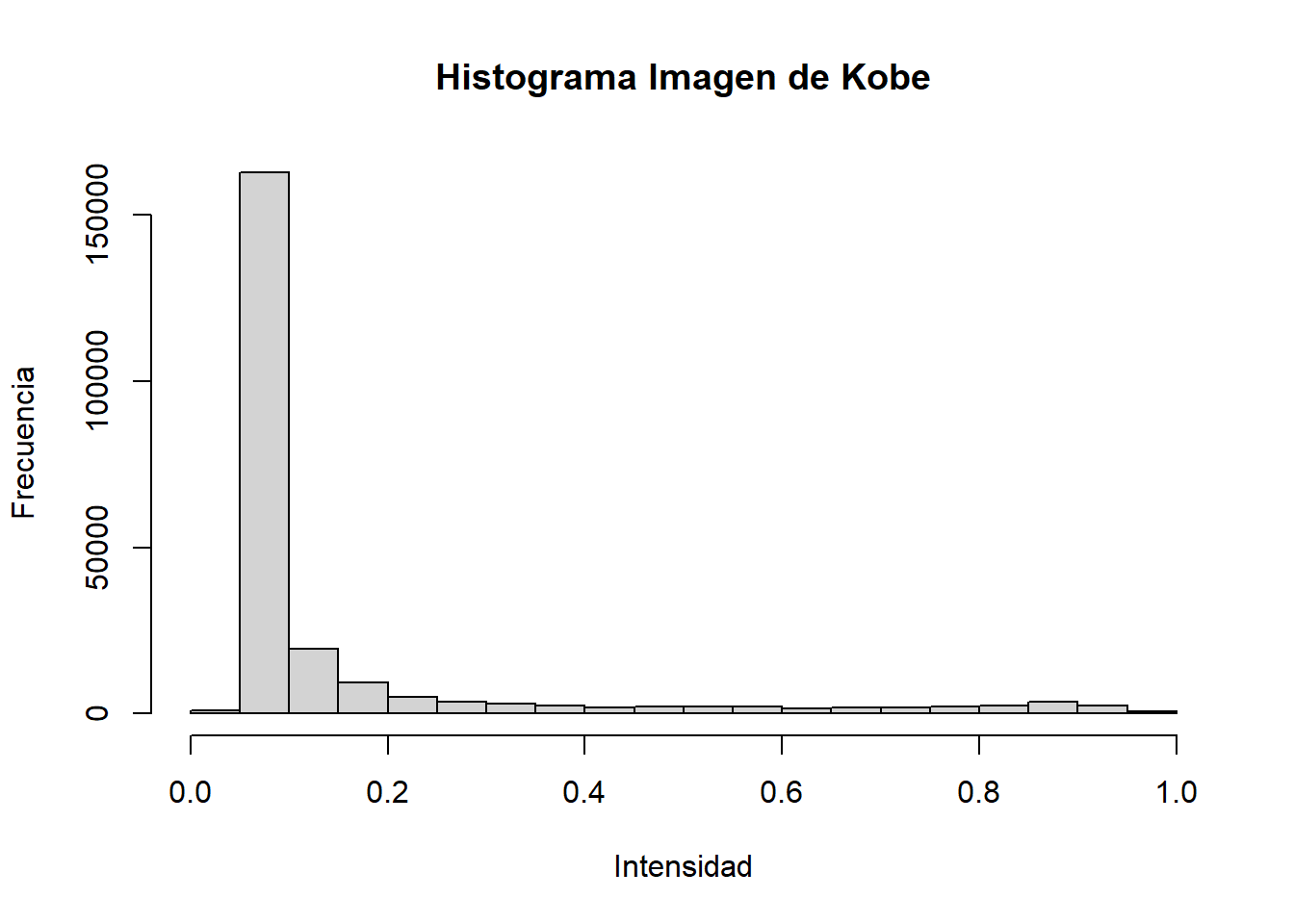
print(kobe_img)## Image. Width: 640 pix Height: 360 pix Depth: 1 Colour channels: 1En escala de grises, cada pixel adopta un valor de 0 a 1. Es posible hacer un histograma de la imagen para confirmar eso (tenía siglos que no hacía un gráfico con las funciones básicas de R).
hist(
kobe_img,
main = "Histograma Imagen de Kobe",
ylab = "Frecuencia",
xlab = "Intensidad"
)
Ya que comprendemos la forma en la que R interpreta cada pixel de las imágenes, hablemos un poco de cómo los representa (almacena). En general uno percibe o piensa en una imagen como una matriz \(N\) por \(N\) (en caso de una imagen cuadrada). En R, una imagen con esas dimensiones se almacena en un vector longitud \(N^2\), en el que cada fila de pixeles de la imagen va seguida de otra, de modo que los primero N valores del vector representa la primera fila, los segundos N valores representan la segunda fila y así sucesivamente
\[X = (x_1, x_2, x_3 . . x_{N^2})\]
Es mucho más intuitivo trabajar con dataframes, por lo que aprovecharemos para convertir el objeto cimg a data.frame. Por defecto el método de la función as.data.frame() convierte las imágenes a un data frame largo (por la manera en la que se R representa las imágenes), de modo que usaremos la función tidyr::spread() para ponerla en formato ancho (aun no sé hacer PCA con data en formato tidy y tampoco me he dedicado a usar la función tidyr::pivot_wider() que sustituyó a spread()).
# Transformando el objto a data.frame
kobe_df <- kobe_img %>%
as.data.frame() %>%
spread(y, value) %>%
select(-x)
# consultar las primeras filas y columnas
kobe_df[1:3, 1:3]## 1 2 3
## 1 0.09803922 0.09411765 0.09411765
## 2 0.10588235 0.10196078 0.09803922
## 3 0.10588235 0.10588235 0.10588235Corriendo el modelo
La función básica para hacer PCA en R es prcomp(), la cual recibe la data y otros argumentos, entre ellos una especificación de si los datos deben ser reescalados. Por convención lo ponemos TRUE, en este caso no es tan necesario, porque por defecto todas las columnas del data frame están en la misma escala, pero cuando aplicamos el ejercicio en set de datos con variables de diferentes unidades, siempre es buena idea ajustar la escala y el centro para evitar que la diferencia en magnitudes de algunas variables las haga parecer que están más asociadas que otras.
kobe_pca <- prcomp(kobe_df, scale. = TRUE, center = TRUE)Ya que tenemos el resumen de la imagen, veamos cuantas componentes principales fueron necesarias para resumirla. Lo mejor es hacer esto con un gráfico porque en general hay muchos componentes e imprimir los valores de cada uno sería un desastre.
kobe_pca %>%
broom::tidy(matrix = "pcs") %>%
ggplot(aes(x = PC, y = cumsum(percent))) +
geom_line() +
theme_minimal() +
labs(x = "Componentes",
y = "Porcentaje de varianza explicada",
title = "Scree plot")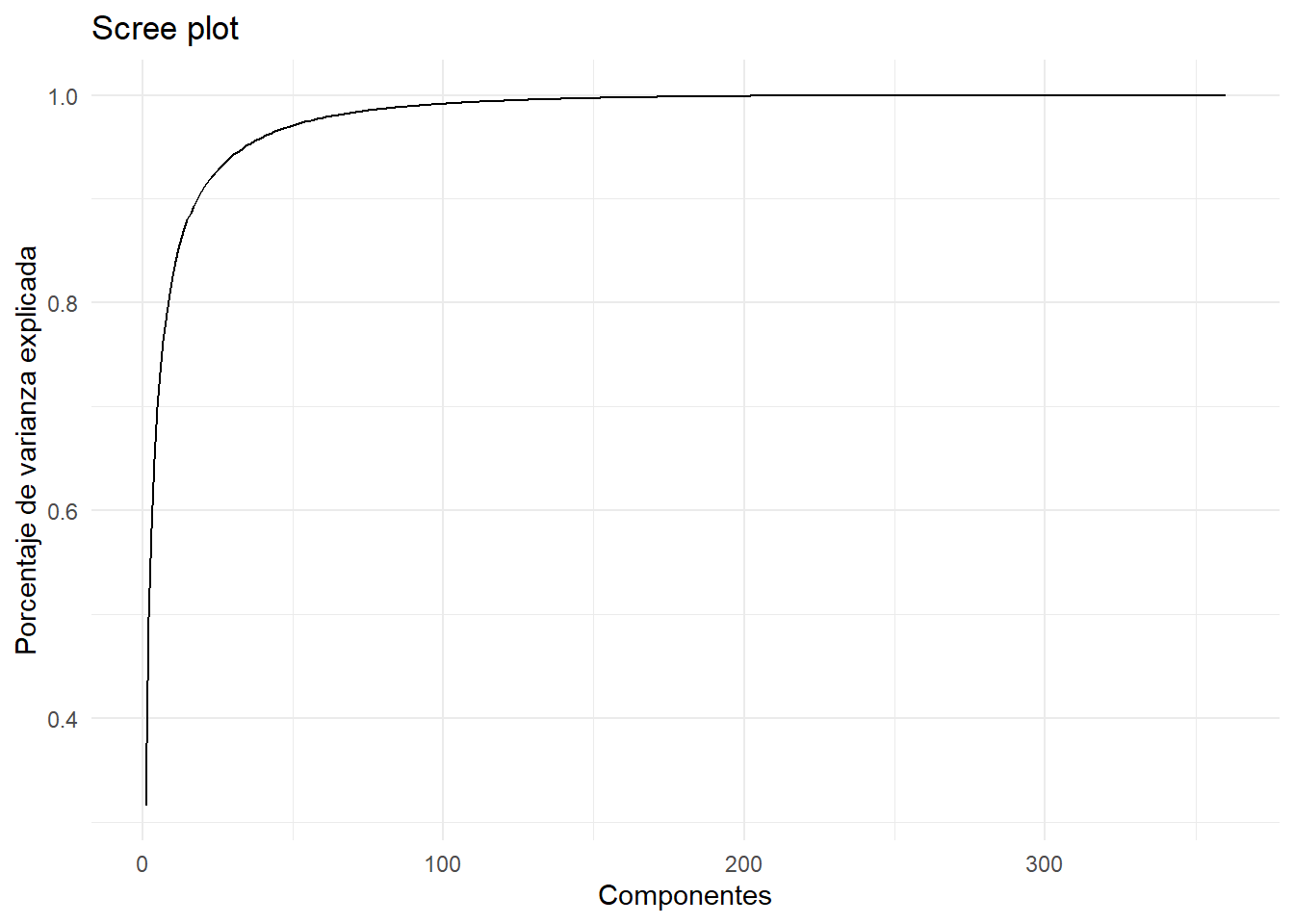
Recuerden que empezamos con una imagen con 640 columnas (pixeles de ancho) y ahora terminamos con cerca de 350 componentes, de los cuales los 100 que explican la mayor cantidad de varianza acumulan cerca del 100% de la varianza total.
Vamo pa’tra, a reconstruir la imagen original con un subset de componentes principales
Cuando hablamos las condiciones que cumplía el PCA como “buen resumen” de un set de datos, se estableció que era importante que a partir de este se pueda aproximar aceptablemente la data original, en este caso la imagen original. Este apartado de la publicación busca explicar cómo recrear el set de datos original a partir de las componentes principales.
En esta parte nos auxiliaremos del blogpost de Kieran Healy que en su momento realizó este ejercicio para una imagen de Elvis y el presidente Nixon.
Lo primero que debemos saber antes de recuperar los valores originales dado el objeto prcomp es, qué elementos contiene y cómo pueden ser utilizados para lograr lo que queremos.
names(kobe_pca)## [1] "sdev" "rotation" "center" "scale" "x"Todo objeto prcomp es una lista que tiene al menos estos 5 componentes:
sdevque contiene la desviación estándar de las componentes principales.rotationque es una matriz con las correlaciones, o pesos de cada variable en cada componente. Aquí cada fila es una variable y cada columna un componente principal.centeryscaleson valores con parámtreos de reescala de cada observación.xes una matriz de la misma dimensión de la data original que contiene las observaciones rotadas y multiplicadas por la matrizrotation.
Con estos objetos, para recuperar la data original simplemente hay que multiplicar x por la matriz rotation transpuesta y revertir el proceso de reescalado si se especificó al correr el algoritmo.
Para recuperar la data original en toda su expresión tendríamos que utilizar las 300 y pico de columnas de las matrices x y rotation, pero como vimos que menos de 100 componentes principales explican prácticamente toda la varianza de los datos, nos limitaremos a ver cómo termina la imagen si la reconstruimos con distintas cantidades de componentes principales.
La función que aparece a continuación la creó Kieran Healy, aquí la utilizaremos para hacer los cálculos descritos en párrafos anteriores usando los elementos de kobe_pca. Esta función recibe un objeto prcomp y el número de componentes que se desean utilizar para aproximar la data original.
# Ojo, esta función la creó Kieran Healy
# no fue idea mía
reverse_pca <- function(n_comp = 20, pca_object = kobe_pca){
## The pca_object is an object created by base R's prcomp() function.
## Multiply the matrix of rotated data by the transpose of the matrix
## of eigenvalues (i.e. the component loadings) to get back to a
## matrix of original data values
recon <- pca_object$x[, 1:n_comp] %*% t(pca_object$rotation[, 1:n_comp])
## Reverse any scaling and centering that was done by prcomp()
if(all(pca_object$scale != FALSE)){
## Rescale by the reciprocal of the scaling factor, i.e. back to
## original range.
recon <- scale(recon, center = FALSE, scale = 1/pca_object$scale)
}
if(all(pca_object$center != FALSE)){
## Remove any mean centering by adding the subtracted mean back in
recon <- scale(recon, scale = FALSE, center = -1 * pca_object$center)
}
## Make it a data frame that we can easily pivot to long format
## (because that's the format that the excellent imager library wants
## when drawing image plots with ggplot)
recon_df <- data.frame(cbind(1:nrow(recon), recon))
colnames(recon_df) <- c("x", 1:(ncol(recon_df)-1))
## Return the data to long form
recon_df_long <- recon_df %>%
tidyr::pivot_longer(cols = -x,
names_to = "y",
values_to = "value") %>%
mutate(y = as.numeric(y)) %>%
arrange(y) %>%
as.data.frame()
recon_df_long
}Teniendo esta función, ya resulta simple reconstruir la imagen original. En este caso haremos un proceso iterativo para probar como queda la imagen con distintas componentes principales y ver en que cantidad de componentes el resultado satisface el objetivo inicial de aproximar adecuadamente el set de datos original.
## Secuencia de componentes principales que deseamos
n_pcs <- c(2, 5, 10, 20, 50, 100)
names(n_pcs) <- paste("Primeras", n_pcs, "Componentes", sep = "_")
## aplicar reverse_pca() a cada n_pcs
recovered_imgs <- map_dfr(
n_pcs,
reverse_pca,
.id = "pcs"
) %>%
mutate(pcs = stringr::str_replace_all(pcs, "_", " "),
pcs = factor(pcs, levels = unique(pcs), ordered = TRUE))El objeto recovered_img es un dataframe bastante largo, contiene en formato tidy. En este la columna pcs dice a qué iteración pertenece el resultado, si a la imagen reconstruida con 2, 5 u otra cantidad de componentes principales. La variables x y y indican la posición del pixel y el campo value tiene la intensidad.
glimpse(recovered_imgs)## Rows: 1,382,400
## Columns: 4
## $ pcs <ord> Primeras 2 Componentes, Primeras 2 Componentes, Primeras 2 Compo~
## $ x <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 1~
## $ y <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1~
## $ value <dbl> 0.10262224, 0.10099415, 0.09911647, 0.09776928, 0.09646917, 0.09~Ya es hora de ver el resultado final, pero antes una pequeña aclaración sobre aspectos relacionados a los ejes de las imágenes. Normalemte estamos acostumbrados tener coordenadas de pares ordenados del tipo \((x_1, y_1), (x_2, y_2)... (x_n, y_n)\) pero las imágenes en R tiene el eje de la ordenada al revés \((x_1, y_n), (x_2, y_{n-1})... (x_n, y_1)\) por eso a la hora de graficar las imágenes usamos la función scale_y_reverse() de ggplot2.
p <- ggplot(
data = recovered_imgs,
mapping = aes(x = x, y = y, fill = value)
)
p_out <- p + geom_raster() +
scale_y_reverse() +
scale_fill_gradient(low = "black", high = "white") +
facet_wrap(~ pcs, ncol = 2) +
guides(fill = FALSE) +
labs(
title = paste0("Recuperando la imagen de Kobe ",
"con distinta cantidad de ",
"componentes principales")
) +
theme(strip.text = element_text(face = "bold", size = rel(1.2)),
plot.title = element_text(size = rel(1.5)))## Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
## "none")` instead.p_out +
theme_minimal() +
labs(x = "", y = "")
Ese es el resultado. En general queda demostrado que un resumen con las primeras 100 componentes principales o hasta las primeras 50 componentes son suficiente para tener una versión decente de la imagen original. Espero que este ejercicio ayude de una forma u otra a entender el valor que agrega usar este tipo de técnicas viendo un ejemplo como este. Sin dudas ver este tema aplicado de esta manera agregará un poco de confianza en los resultados cuando hagamos un modelo usando data con dimensionalidad reducida.
Ahora para terminar, la imagen original en todo su esplendor.
plot(kobe_img, main = "Hasta siempre Kobe")
Referencias
Todas las publicaciones que coloco aquí aportaron de gran maneran al desarrollo de esta publicación. Principalmente la publicación de Kieran Healy.
Para una explicación bien detallada y estructurada de esta técnica, les recomiendo el capítulo 6.3 del libro An Introduction to Statistical Learning.
- https://kieranhealy.org/blog/archives/2019/10/27/reconstructing-images-using-pca/
- https://www.datacamp.com/community/tutorials/pca-analysis-r
- https://stats.stackexchange.com/questions/2691/making-sense-of-principal-component-analysis-eigenvectors-eigenvalues
- https://cran.r-project.org/web/packages/imager/vignettes/gettingstarted.html
- https://ourarchive.otago.ac.nz/bitstream/handle/10523/7534/OUCS-2002-12.pdf?sequence=1&isAllowed=y
- https://cerebralmastication.com/2010/09/principal-component-analysis-pca-vs-ordinary-least-squares-ols-a-visual-explination/
comments powered by Disqus